Privacy in Public: A Case Study on Privacy Pools

- Privacy Pools is live on 4 chains (Ethereum, Optimism, BSC, Arbitrum) across 21 pools, with ~$5.78M of TVL, ~5,180 lifetime deposits, ~5,630 withdrawals, and a healthy mainnet ETH pool of 2,320 distinct depositors behind a strong anonymity set.
- The protocol's ZK proof hides which deposit funded which withdrawal cryptographically. Public-data signals an outside observer could attempt to read are heuristic only, and the protocol's design (open ragequit, free decoy construction, relayer flow) makes those heuristics impossible to verify from on-chain data alone.
- Indexed end-to-end with one Envio HyperIndex v3 indexer, ClickHouse storage, and a thin Uniswap V4 price feed on BSC. Full multichain sync to head: ~30 seconds.
- Full open-source code, queries, and BI report generator at github.com/enviodev/privacy-pools.
Privacy Pools is one of the more ambitious privacy primitives shipped on Ethereum and its L2s. The protocol, co-authored by Vitalik Buterin and others, pairs a zero-knowledge proof of pool membership with an off-chain compliance vetting layer (the Association Set Provider, ASP). The result is a privacy mechanism that gives users cryptographic unlinkability between their deposit and their withdrawal, while still letting an off-chain layer say "we don't think this commitment came from a sanctioned address". Both halves matter, and both halves are working.
This post walks through a fully indexed snapshot of every deposit, withdrawal, ragequit, ASP root update, and relayer fee across all 21 live pools on every chain Privacy Pools runs on (14 on Ethereum, 2 on Optimism, 2 on BSC, 3 on Arbitrum). The headline takeaways are positive: the ZK proof is sound, the relayed-withdrawal path that preserves privacy gets used by 91% of withdrawers, and the largest pool has a genuinely diverse depositor base. The smaller, newer pools are doing what newer pools do: building toward those numbers.
The interesting analytical question, then, is what an outside observer with the public on-chain data can or can't say about who linked to whom. The answer is a clean "very little, and never with certainty". This is by design, and the data shows the design holding.
The full stack (indexer, analytics queries, BI report generator) is open-source at github.com/enviodev/privacy-pools under MIT license.
What is Privacy Pools
Three on-chain entities matter for indexing:
- The Entrypoint: the singleton each pool registers under. Routes deposits and relays withdrawals.
- PrivacyPool: one contract per asset (ETH, USDC, USDT, fxUSD, BOLD, and so on). Emits
Deposited,Withdrawn,Ragequit,LeafInserted,PoolDied. - Association Set Provider (ASP): off-chain vetting. On-chain footprint is the
RootUpdatedevents from the Entrypoint, each carrying a Merkle root and an IPFS pointer to the approved set.
The deposit/withdraw flow produces a commitment in a per-pool Merkle tree on deposit, and on withdrawal proves "I own some commitment in this pool, and that commitment is in the Association Set approved by the ASP", without revealing which commitment. Ragequit is the escape hatch: a depositor whose commitment has been excluded from a recent ASP root pulls their position out without the ZK-protected withdrawal flow.
The Dataset
The indexer covers every Entrypoint and every PrivacyPool live across the four supported chains. Headline state at the time of writing (block heights are real-time):
| chain | pools | deposits | withdrawals | ragequits | leaves |
|---|---|---|---|---|---|
| Ethereum | 14 | 4,731 | 5,138 | 322 | 9,883 |
| Optimism | 2 | 124 | 128 | 37 | 254 |
| BSC | 2 | 60 | 20 | 45 | 82 |
| Arbitrum | 3 | 265 | 344 | 36 | 612 |
| Total | 21 | 5,180 | 5,630 | 440 | 10,831 |
USD TVL across all chains: ~$5.78M. Largest pools:
| pool | TVL (USD) |
|---|---|
| Ethereum USDT | $2.40M |
| Ethereum ETH | $1.75M |
| Ethereum USDC | $1.46M |
The mainnet ETH pool: a working anonymity set
The Ethereum ETH pool is the protocol's flagship deployment, and its numbers tell a clear story:
- 2,320 distinct depositors (the next-largest cohort is 253 on Ethereum USDC).
- 7,889 leaves in the Merkle tree, more than every other pool combined.
- Herfindahl-Hirschman Index of 132 on depositor-value share, far below the 2,500 threshold considered "highly concentrated". The top depositor controls 8.0% of value, the top five 17.4%, the top ten 24.7%. There is no dominant wallet.
Together those numbers describe a pool with real anonymity. A withdrawal from this pool has thousands of plausible commitments behind it, and no single dominant depositor for an analyst to single out.
The smaller pools (BNB on BSC, yUSND on Arbitrum, BOLD on Ethereum, and the rest of the long tail) are at much earlier points in the same curve. With anywhere from 1 to ~250 leaves, the long tail is in early-cohort phase. Concentration is high there because the pools are young, not because the protocol is broken.
Anonymity-set growth
Each commitment lives as a leaf in the per-pool Merkle tree. Both deposits and the ZK-replacement leaves emitted on withdrawal contribute, so the leaf count keeps climbing as the pool gets used.
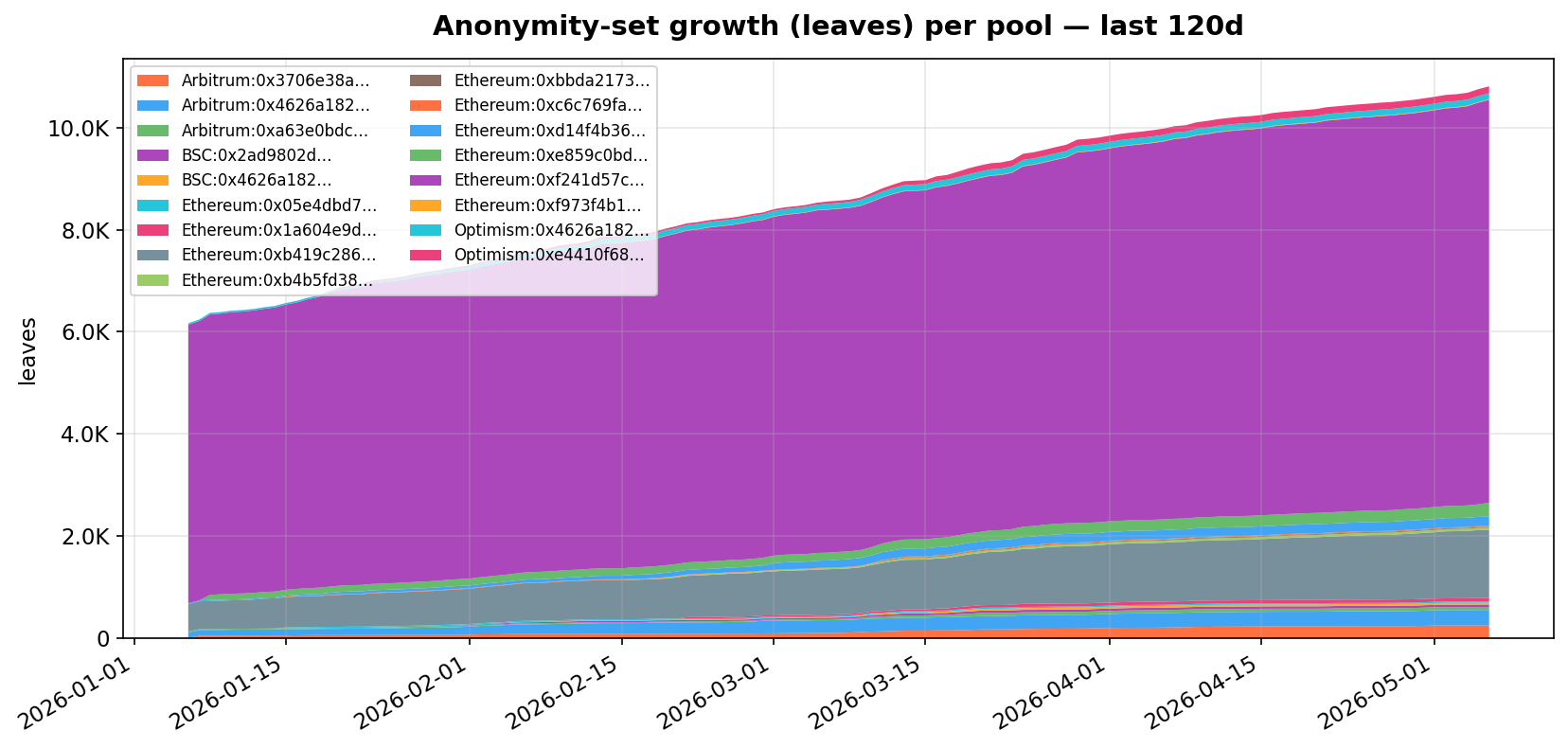
The Ethereum ETH pool dominates by volume, but every active pool shows steady growth. There is no sign of pool abandonment.
Activity patterns
Aggregating deposits and withdrawals by hour-of-day and day-of-week (UTC) reveals a global usage pattern: activity is roughly continuous, with a mild ramp through European and US business hours and a softer Asia-Pacific tail. Privacy Pools is being used as a steady utility, not as an event-driven product.
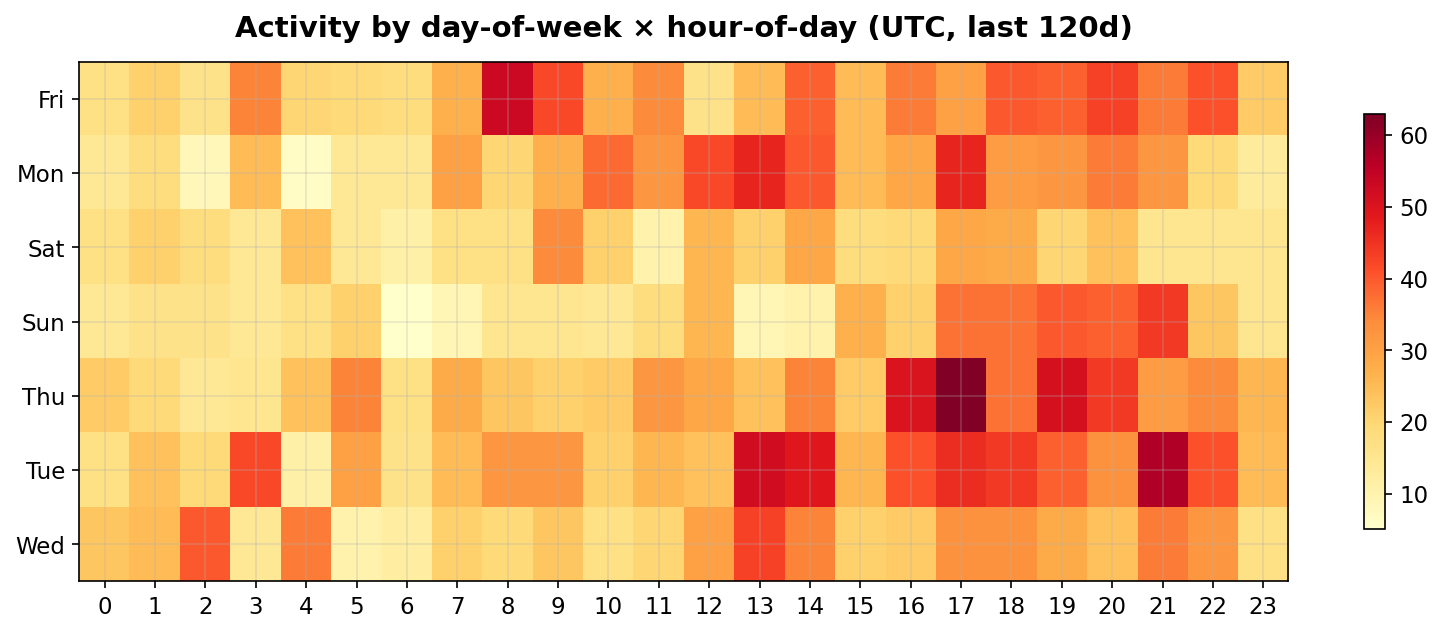
The lack of strong timezone clustering is itself a privacy positive: a sharply timezone-skewed user base would be an inadvertent fingerprint. This data shows a globally distributed user set.
Relayed-withdrawal share
Withdrawals can be self-submitted (the recipient submits their own proof, paying gas with their own address) or relayed (a relayer submits on the recipient's behalf, taking a fee). Self-submitted withdrawals link the recipient address to the gas-paying address; relayed withdrawals don't.
Across all chains:
- 5,148 withdrawals were relayed.
- 482 were self-submitted (~8.6%).
91.4% of withdrawals took the privacy-preserving relayed path. That's a strong positive signal: users understand the privacy model and use it.
The relayer market on Ethereum is currently concentrated, with one relayer (0xec15c200…) processing ~77.7% of relayed flow and 0x855b4a60… taking 19.9%. The relayer doesn't see the deposit side, so they can't break the ZK link, but the concentration is worth watching as the relayer ecosystem matures. New relayers entering the market would distribute that observability and is a natural maturation step for the protocol.
Linkability: the public-data heuristic, and why it can never be proof
Take every (deposit, withdrawal) pair in the same pool with the same on-chain value, and a time gap of 60 seconds to 2 hours. Treat the withdrawal as possibly linkable to that deposit by an external observer.
This is a heuristic. There is no proof the same actor controls both addresses, only that the visible flow is consistent with that.
| pool | candidate pairs | total withdrawals | linkable share | median gap |
|---|---|---|---|---|
| Ethereum USDC | 50 | 862 | 5.6% | 61 min |
| Ethereum USDT | 7 | 170 | 3.5% | 57 min |
| Ethereum ETH | 882 | 3,916 | ~10.9% | 39 min |
| Arbitrum USDC | 26 | 150 | 16.0% | 57 min |
| Arbitrum ETH | 28 | 168 | 15.5% | 47 min |
| Optimism ETH | 13 | 60 | 15.0% | 61 min |
| BSC USDT | 3 | 8 | 37.5% | 25 min |
| Ethereum USDS | 3 | 8 | 37.5% | 4 min |
About one in ten Ethereum ETH withdrawals fits this shape. On the smaller pools, the share is higher because there are fewer deposits to lose oneself in. These are upper bounds on what a naive heuristic can flag, and they are not proofs. The next section shows why.
Decoy withdrawals: how the protocol absorbs the heuristic
The same-amount heuristic has a known counter, and it is a feature of the privacy model rather than a workaround.
An existing depositor whose funds have been in the pool for weeks or months sees a fresh deposit hit the contract. They withdraw an equivalent amount within the heuristic's time window, to a fresh address that has nothing to do with the new depositor. An outside observer running the same-amount analysis links the new deposit to that withdrawal address.
From outside, the pair looks like "Alice deposited and Alice (the withdrawal recipient) withdrew shortly after". Inside, Alice and the withdrawal recipient have nothing to do with each other. The withdrawer's funds predate Alice entirely.
Querying for deposits followed within 30 minutes by a same-amount withdrawal where the depositor and the withdrawal recipient are different addresses:
- 393 decoy-candidate pairs across the dataset.
- 163 distinct depositors had a same-amount withdrawal land within 30 minutes from a different address.
- 160 distinct withdrawal addresses received those decoy-shaped withdrawals.
These are candidates, not proven decoys. Every pair could be one of three things, all indistinguishable from public data:
- The depositor really is the same actor, just routing the receipt through a different address.
- Two unrelated parties happen to transact for the same round amount within minutes (more likely on busy pools and round denominations).
- An existing depositor deliberately constructs the match to spoof the heuristic.
Because option (3) is cheap (one extra withdrawal proof) and option (2) is plausible on common amounts, the linkable-share table above is a plausibility upper bound, not a recall figure. An actor who knows the heuristic exists can deliberately produce false matches, and an actor who is genuinely the same person across both addresses will also show up in the same table. This is the verifiability ceiling that the protocol's design relies on, and it does the load-bearing work of converting the cryptographic guarantee into practical anonymity. Plausible deniability is real precisely because it can never be ruled out from public data.
Ragequit: the safety valve doing its job
Ragequit is the escape hatch. When the ASP excludes a commitment from the latest approved root, the depositor still gets their funds back, just through a path that reveals which commitment they originally made.
The mainnet ETH baseline is 6.0% ragequit-by-count, 9.2% by value. The smaller pools have higher rates:
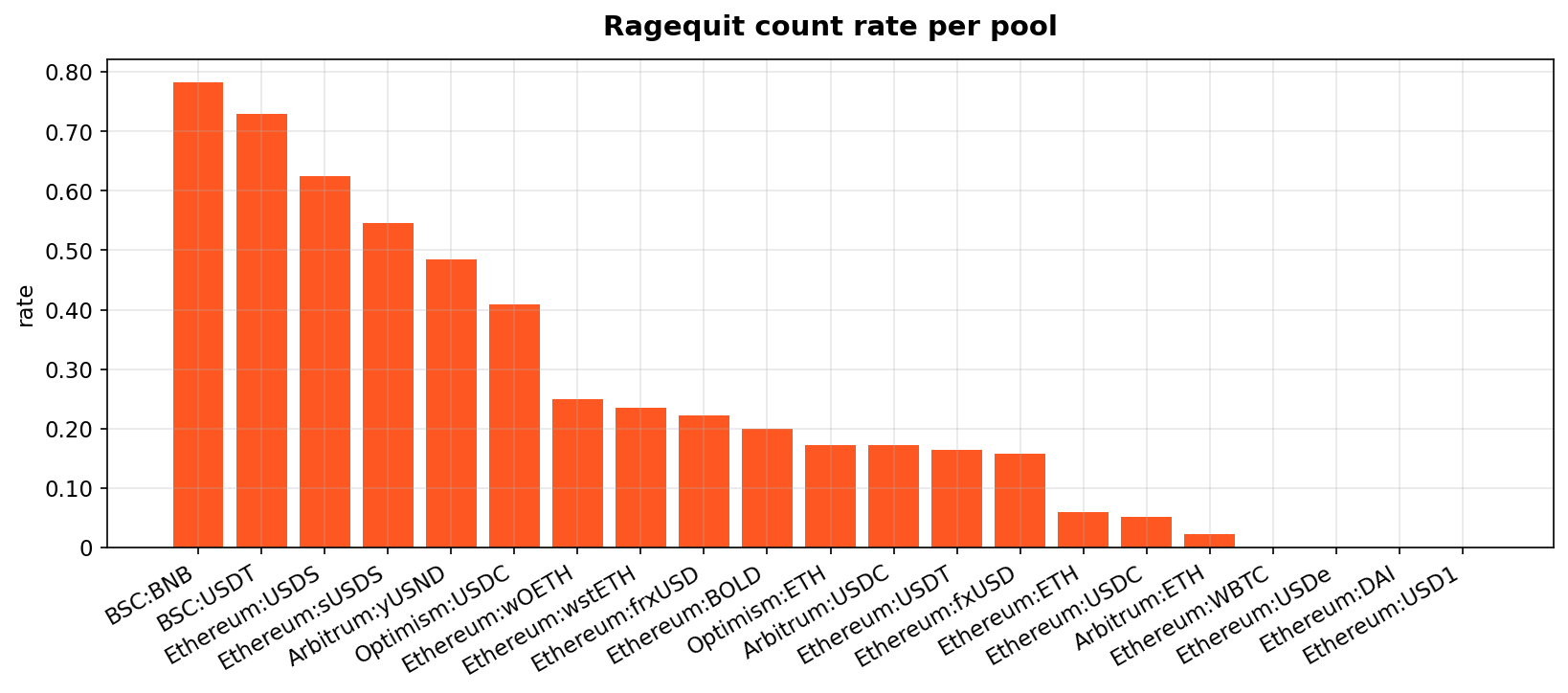
| pool | ragequit % (count) | ragequit % (value) |
|---|---|---|
| BSC BNB | 78.3% | 97.1% |
| Arbitrum yUSND | 48.5% | 90.7% |
| BSC USDT | 72.9% | 78.6% |
| Ethereum USDS | 62.5% | 58.7% |
| Ethereum sUSDS | 54.5% | 35.7% |
| Ethereum fxUSD | 15.8% | 33.2% |
| Ethereum wstETH | 23.5% | 24.0% |
| Ethereum ETH | 6.0% | 9.2% |
Three pools (BSC BNB, Arbitrum yUSND, BSC USDT) have seen most of their deposit value exit through the ragequit path rather than ordinary withdrawals. Depositors did not lose funds, they got their money back. What was lost on those specific commitments was the cryptographic privacy property, because ragequit reveals which commitment exited.
This is the ASP doing what it is designed to do: rejecting commitments after the fact when the off-chain compliance check changes its mind, and giving users a way out that doesn't trap their funds. The fact that the escape hatch is being exercised on the edges (small, young pools) is the system's compliance layer working as advertised, and it doesn't affect the privacy of any other depositor. For the mainnet ETH pool, where the bulk of activity sits, the ragequit rate is low and stable.
Where the public-data layer helps
A privacy protocol's job is to provide cryptographic guarantees that an external observer can't link who deposited what to who withdrew. Privacy Pools does that: the ZK proof is sound, the verifiers are deployed, the on-chain mechanism works.
What the on-chain trail also does is record every deposit value, every withdrawal value, every relayer address, every recipient, and every timestamp. From that an indexed dataset gives you:
- A linkable-share number per pool (5-37% across the indexed pools), constrained by the verifiability ceiling above.
- A concentration index per pool that tells you how mature the anonymity set is.
- A ragequit-rate signal that confirms the ASP layer is active and that the safety valve is functioning.
- A relayed-share number showing 91% of withdrawers using the privacy-preserving path.
- A decoy-candidate count that quantifies how much credibility the plausible-deniability layer has on each pool.
None of these break the protocol. None of these are verifiable. All of them are useful operational metadata that anyone, including the ASP, the protocol team, and end users, can use to track the protocol's health.
The point of indexing the protocol publicly is precisely that this kind of monitoring should be open. The same dataset that enables the heuristics also exposes the limits of those heuristics, and lets honest actors and the protocol team work on the things that actually matter (anonymity-set growth on the long-tail pools, relayer-market diversification, ASP responsiveness) without anyone needing privileged access.
What this isn't
A few things this analysis explicitly does not show:
- It does not break the ZK proof. Every linkability claim above is heuristic. A withdrawal that matches a deposit by amount and timing is consistent with the same actor controlling both addresses, but it is not proof.
- The decoy-candidate count is not a fraud detector. Many of the 393 decoy-shaped pairs will be coincidence on common round amounts, and some will be the same actor using a fresh address. The count is a ceiling on intentional decoys, not a measurement of them.
- High-ragequit pools aren't broken. Ragequit firing is the system working as designed when the ASP excludes a commitment.
- The fee figures are operator drains, not gross protocol revenue. The Entrypoint emits post-fee deposit values, so we can only observe the cashflow at the
FeesWithdrawnstep.
Any heuristic an analyst can run, a depositor can game. Anyone can construct decoy patterns at low cost. Anyone can split deposits across rounds, jitter timing, and rotate recipient addresses. Public-data heuristics are a probability surface, not a truth function. Privacy Pools is built for exactly that constraint.
How this was indexed
The full stack is one Envio HyperIndex v3 indexer running locally with dual Postgres + ClickHouse storage:
- One config, four chains: Ethereum (1), Optimism (10), BSC (56), Arbitrum (42161). Same
EntrypointandPrivacyPoolABIs reused across all four. The L2s share a deterministic0x44192215…Entrypoint via CreateX, while mainnet has the original0x6818809E…. - One handler set writes 9 entity types:
Pool,Deposit,Withdrawal,Ragequit,MerkleLeaf,AssociationSetRoot,Account,FeeWithdrawal, plus a derivedLatestPrice/TokenPricepair from a thin Uniswap V4 price feed on BSC. All chain-scoped IDs ({chainId}_{address}) so the L2 ETH-pool address collision (0x4626…918ffis the ETH pool on Optimism, BSC, and Arbitrum) doesn't fold rows together. - Multichain sync to head: ~30 seconds. HyperSync handles 4 chains in parallel; the only non-trivial cost is the V4 price feed, which we keep cheap by starting near BSC's head and filtering Swap events to ~70 hardcoded pricing-pool IDs (see Uniswap V4 deployments). No Initialize handler, no historical V4 backfill, just current prices.
- Analytics on ClickHouse. A Python
analytics/package runs the headline queries throughclickhouse-connect, charts them with matplotlib, and assembles a markdown BI report that renders to PDF viareportlab. The full report regenerates in a couple of seconds against the live ClickHouse.
The schema and the SQL queries are designed for this kind of question. Adding a new heuristic, say "deposits whose precommitment hash has a leading-zero prefix", is an .sql file, not a re-index.
Reproducing this
The full stack lives at github.com/enviodev/privacy-pools under MIT license. One HyperIndex v3 indexer plus a Python analytics package that ships the BI report generator and every saved query.
config.yaml,schema.graphql,src/EventHandlers.ts,src/v4Pricing.ts,src/v4PoolMeta.ts: the indexer.analytics/queries/{health,anonymity,risk,asp,relayers,fees,activity,pricing}/*.sql: every metric in this post.analytics/scripts/generate_bi_report.py: assembles the report markdown plus 6 charts.analytics/scripts/render_pdf.py: markdown to PDF, including image embedding.
git clone https://github.com/enviodev/privacy-pools
cd privacy-pools
cp .env.example .env # add your free ENVIO_API_TOKEN from envio.dev
pnpm install
pnpm envio start
# in another shell
cd analytics
cp .env.example .env
uv sync
uv run python scripts/generate_bi_report.py
Multichain sync completes in well under a minute. The BI report regenerates against live ClickHouse in seconds.
If you want to extend the analysis (chain-cross transitive linkability, ASP root vs deposit timing, relayer-collusion graphs, or anything else), every entity carries chainId and blockNumber, and the schema is documented end-to-end in analytics/CLAUDE.md.
Build with Envio
Envio HyperIndex is independently benchmarked as the fastest EVM blockchain indexer available. The Privacy Pools indexer is one example of what's possible when multichain coverage and an analytics-grade columnar store are first-class features. If you're building onchain (DeFi, prediction markets, gaming, or something nobody has thought of yet), the docs are the starting point.
- Repo: https://github.com/enviodev/privacy-pools
- Docs: https://docs.envio.dev/
- Discord: https://discord.gg/envio
- Telegram: https://t.me/+BeS5ihVUFONjNGFk
- X: https://x.com/envio_indexer