Understanding Multichain Indexing
For a conceptual overview of what multichain indexing is and when to use it, see What is multichain indexing?. This page covers the HyperIndex configuration and patterns.
Multichain indexing allows you to monitor and process events from contracts deployed across multiple blockchain networks within a single indexer instance. This capability is essential for applications that:
- Track the same contract deployed across multiple networks
- Need to aggregate data from different chains into a unified view
- Monitor cross-chain interactions or state
How It Works
With multichain indexing, events from contracts deployed on multiple chains can be used to create and update entities defined in your schema file. Your blockchain indexer will process events from all configured networks, maintaining proper synchronization across chains.
Configuration Requirements
To implement multichain indexing, you need to:
- Populate the
chainssection in yourconfig.yamlfile for each chain - Specify contracts to index from each chain
- Create event handlers for the specified contracts
Real-World Example: Uniswap V4 Multichain Indexer
For a comprehensive, production-ready example of multichain indexing, we recommend exploring our Uniswap V4 Multichain Indexer. This official reference implementation:
- Indexes Uniswap V4 deployments across 10 different blockchain chains
- Powers the official v4.xyz interface with real-time data
- Demonstrates best practices for high-performance multichain indexing
- Provides a complete, production-grade implementation you can study and adapt
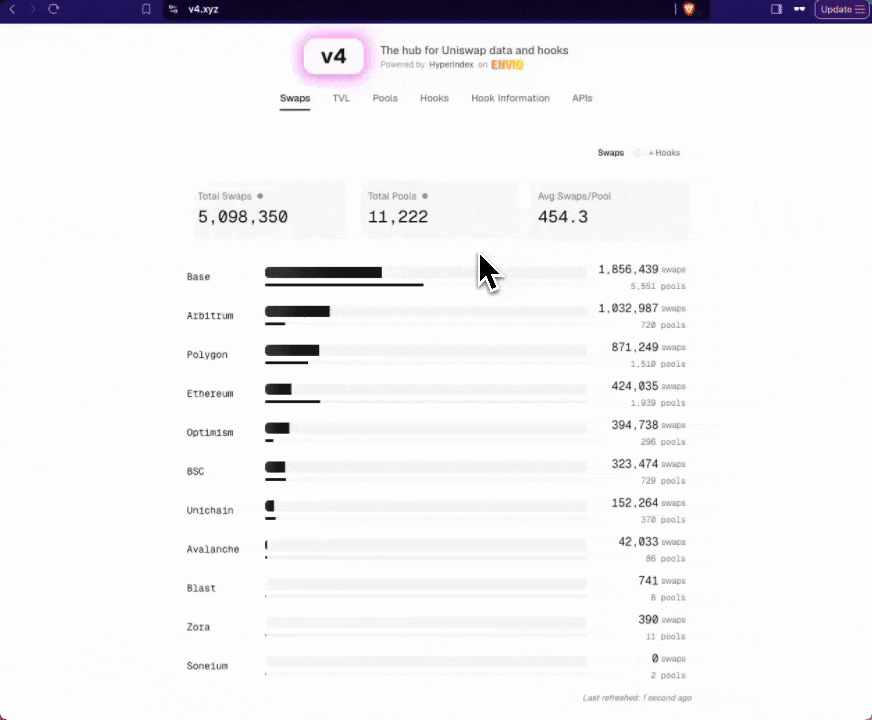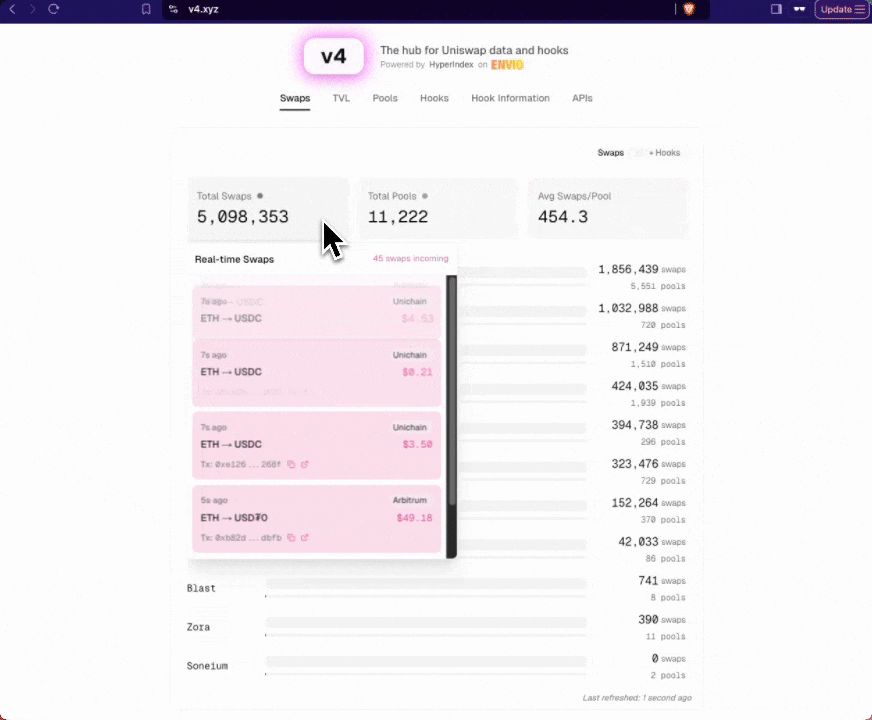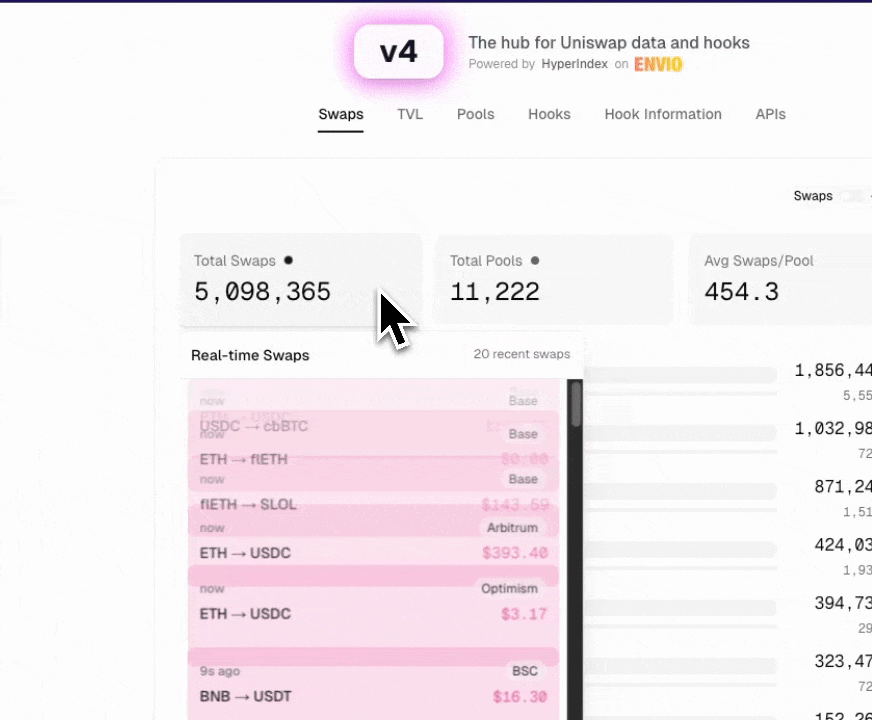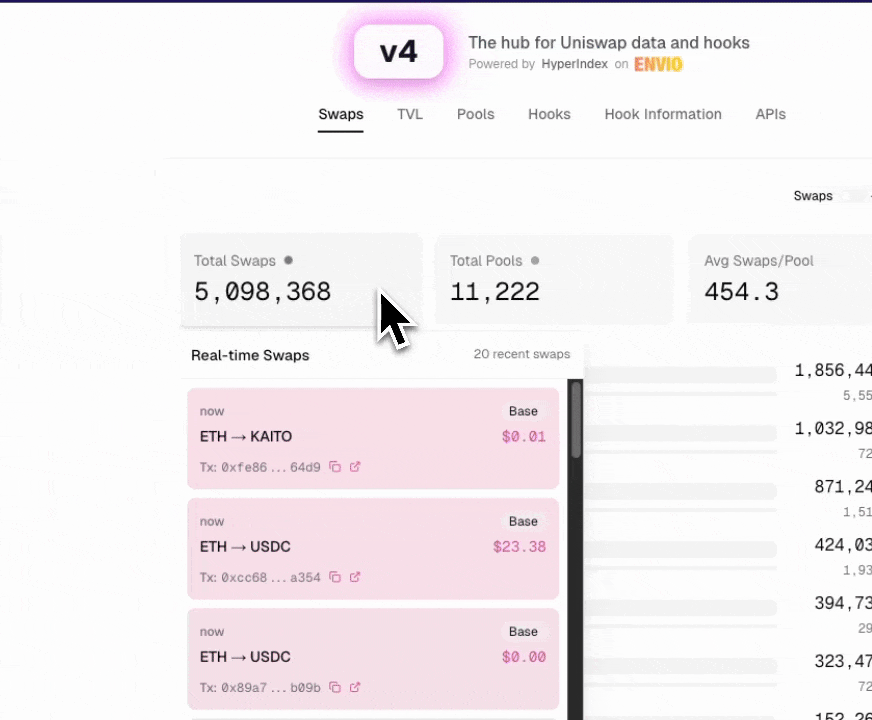
The Uniswap V4 indexer showcases how to effectively structure a multichain indexer for a complex DeFi protocol, handling high volumes of data across multiple networks while maintaining performance and reliability.
Config File Structure for Multichain Indexing
The config.yaml file for multichain indexing contains three key sections:
- Global contract definitions - Define contracts, ABIs, and events once
- Chain-specific configurations - Specify chain IDs and starting blocks
- Contract instances - Reference global contracts with chain-specific addresses
# Example structure (simplified)
contracts:
- name: ExampleContract
abi_file_path: ./abis/example-abi.json
events:
- event: ExampleEvent
chains:
- id: 1 # Ethereum Mainnet
start_block: 0
contracts:
- name: ExampleContract
address: "0x1234..."
- id: 137 # Polygon
start_block: 0
contracts:
- name: ExampleContract
address: "0x5678..."
Key Configuration Concepts
- The global
contractssection defines the contract interface, ABI, handlers, and events once - The
chainssection lists each blockchain chain you want to index - Each chain entry references the global contract and provides the chain-specific address
- This structure allows you to reuse the same handler functions and event definitions across chains
📢 Best Practice: When developing multichain indexers, append the chain ID to entity IDs to avoid collisions. For example:
user-1for Ethereum anduser-137for Polygon.
Multichain Event Ordering
In V3 the indexer always processes multichain events in unordered mode. Events from different chains are processed as soon as they're available, without waiting for the other chains, which keeps latency low.
- Events are still processed in order within each individual chain.
- Events across different chains may be processed out of order.
- Processing happens as soon as events are emitted, so you don't wait for the slowest chain's block time.
This is ideal when:
- Operations on your entities are commutative (order doesn't matter).
- Entities from different chains never interact with each other.
- Processing speed matters more than guaranteed cross-chain ordering.
The V2 unordered_multichain_mode option, the multichain: ordered opt-in, and the UNORDERED_MULTICHAIN_MODE / UNSTABLE__TEMP_UNORDERED_HEAD_MODE environment variables have all been removed in V3 — there is nothing to configure.
Ordered Multichain Mode
HyperIndex V3 doesn't offer an ordered multichain mode, and it's a deliberate choice rather than a feature gap. Ordered mode worked by pausing every chain until events from the slowest chain had caught up, so the moment one chain hiccuped (RPC rate limits, a slow block, a brief reorg) every other chain stalled with it. In practice that meant a multichain indexer was only ever as reliable and as fast as its worst-performing chain, and even healthy chains paid for that coupling with significantly higher latency at the head.
You almost always get better reliability and lower latency by keeping every chain unordered and modeling the cross-chain relationship in your schema instead. Each chain writes a small temporary entity when its side of a cross-chain interaction happens, and the second chain (whichever arrives last) reads those temporary entities and finalizes the unified entity. Because each chain progresses independently, none of them are blocked on each other.
A typical pattern for an A → B cross-chain message:
type CrossChainMessage {
id: ID! # The shared cross-chain message id (e.g. nonce + originChainId)
sourceChainId: Int
sourceTxHash: String
destinationChainId: Int
destinationTxHash: String
status: String! # "sent" | "delivered"
}
import { indexer } from "envio";
// Chain A: the message was emitted. Create or update the entity with the
// "sent" side of the data. The destination handler may run before or after.
indexer.onEvent(
{ contract: "Bridge", event: "MessageSent" },
async ({ event, context }) => {
const id = `${event.params.originChainId}-${event.params.nonce}`;
const existing = await context.CrossChainMessage.get(id);
context.CrossChainMessage.set({
id,
sourceChainId: event.chainId,
sourceTxHash: event.transaction.hash,
destinationChainId: existing?.destinationChainId,
destinationTxHash: existing?.destinationTxHash,
status: existing?.destinationTxHash ? "delivered" : "sent",
});
},
);
// Chain B: the message was delivered. Read the (maybe-already-existing)
// entity and fill in the destination side, regardless of which side arrived
// first.
indexer.onEvent(
{ contract: "Bridge", event: "MessageDelivered" },
async ({ event, context }) => {
const id = `${event.params.originChainId}-${event.params.nonce}`;
const existing = await context.CrossChainMessage.get(id);
context.CrossChainMessage.set({
id,
sourceChainId: existing?.sourceChainId,
sourceTxHash: existing?.sourceTxHash,
destinationChainId: event.chainId,
destinationTxHash: event.transaction.hash,
status: existing?.sourceTxHash ? "delivered" : "sent",
});
},
);
The same shape works for any "rendezvous" where two chains contribute parts of one logical record (bridges, cross-chain governance, multichain user profiles, etc.). The "temporary" entity is just a regular entity that gets progressively completed as each chain's events arrive — there's no special API to learn, and the indexer stays fast and resilient because no chain ever waits on another.
If you have a use case that genuinely cannot be expressed this way, reach out on Discord — we'd like to hear it.
Best Practices for Multichain Indexing
1. Entity ID Namespacing
Always namespace your entity IDs with the chain ID to prevent collisions between chains. This ensures that entities from different chains remain distinct.
2. Error Handling
Implement robust error handling for chain-specific issues. A failure on one chain shouldn't prevent indexing from continuing on other chains.
3. Testing
- Test your indexer with realistic scenarios across all chains
- Use testnet deployments for initial validation
- Verify entity updates work correctly across chains
4. Performance Considerations
- Consider your indexing frequency based on the block times of each chain.
- Monitor resource usage, as indexing multiple chains increases load.
- Adding more chains does not linearly degrade performance — chains are indexed in parallel.
5. Adding a New Chain to an Existing Indexer
To add a new chain to a running indexer:
- Add the new chain entry to your
config.yamlwith the appropriatestart_blockand contract addresses - Push the updated code to your deployment branch (for Envio Cloud) or restart locally with
pnpm envio dev -r
On Envio Cloud, this creates a new deployment that re-indexes all chains (including the new one). Your previous deployment continues serving queries with zero downtime until the new deployment is fully synced. See the deployment guide for details.
Locally, adding a new chain requires a restart and will re-index all chains from their respective start blocks. Note that in V3, envio dev no longer auto-resets the database — pass -r (or --restart) explicitly when you want a fresh sync. envio start is now production-only.
Troubleshooting Common Issues
-
Entity Conflicts: If you see unexpected entity updates, verify that your entity IDs are properly namespaced with chain IDs.
-
Memory Usage: If your indexer uses excessive memory, consider optimizing your entity structure and implementing pagination in your queries.
Next Steps
- Explore our Uniswap V4 Multichain Indexer for a complete implementation
- Review performance optimization techniques for your indexer