Envio Developer Update June 2026
 Jordyn Laurier
Jordyn Laurier
June was one of our biggest months yet. HyperIndex advanced, delivering up to 2.5x faster and 2x cheaper indexing alongside multi-field getWhere filtering, multi-storage defaults, snake_case column naming, and expanded experimental Solana support. We also sponsored and attended ETHConf New York, continued migrating performance-critical paths to Rust, and saw teams ship a range of production-grade, real-time applications on Envio, spanning real-world asset tracking and x402 payment analytics.
Alongside the releases, we published new technical guides on agentic indexing, scaling subgraph-style workloads to millions of requests, choosing between HyperIndex and HyperSync, and much more.
Let's dive in!
HyperIndex v3.1 & v3.2: Faster, Cheaper, and More Flexible
Building on May's V3 launch, June delivered two substantial releases focused on speed, cost, and flexibility, followed by a patch release and the start of work on v3.3.
v3.1
v3.1 cut HyperSync queries during backfill by up to 2x and made many indexing cases up to 2.5x faster. It also added string descriptions for entities, fields, and relationships that surface directly in the GraphQL API, rate-limit information in the TUI and logs, a skip option to exclude chains from indexing and migrations, and support for startups with 4.5M+ contracts. We also improved the agentic development experience with new envio tools search-docs and envio tools fetch-docs commands, plus an envio metrics runtime subcommand.
Up to 2.5x faster indexing, with up to 2x fewer HyperSync queries during backfill.
v3.2
v3.2 followed with multi-field filtering in getWhere, so you can match on several entity fields at once, plus a performance boost for single _eq and _in lookups. Multi-storage got easier with default storages, so you no longer need a @storage directive on every entity, and you can now auto-convert database column names to snake_case while keeping the original names in GraphQL and handler types. We also expanded experimental Solana support with HyperSync-powered instruction handlers. Reach out to us if you are interested in becoming an early tester.
Multi-field filtering with getWhere
Match on several entity fields at once:
await context.Account.getWhere({
id: { _eq: "0x123..." },
balance: { _gte: 1_000_000n, _lte: 10_000_000n },
});
Multi-storage defaults
Mark a storage as default, so you no longer need a @storage attribute on every entity in schema.graphql:
storage:
postgres:
default: true
clickhouse:
default: true
snake_case column names
Auto-convert database column names to snake_case, while GraphQL and handler types keep the original names from schema.graphql:
storage:
postgres:
column_name_format: snake_case
v3.2.1
v3.2.1 rounded out the month with a smoother envio init experience for agents and non-interactive runs, ClickHouse nullable array validation, and faster indexing through topic filtering by address. We have also started work on v3.3.0 in alpha, focused on faster backfills for large multichain indexers.
See the full release notes
Star us on GitHub ⭐
Just-in-Time Indexing: Using Agents to Answer Onchain Questions

Just-in-Time Indexing shows how an AI agent can use Envio to answer one-off onchain questions without maintaining permanent infrastructure. The agent builds the indexer on demand, queries it once, and deletes it.
See how Curve Finance has been using Envio to answer one-off onchain questions with just-in-time indexing.
Read it here: https://docs.envio.dev/blog/just-in-time-indexing-agents-onchain
RWA Radar: Real-World Assets Onchain in Real Time
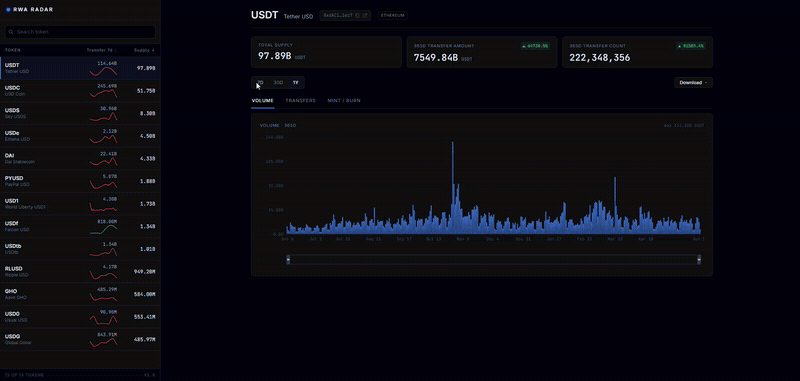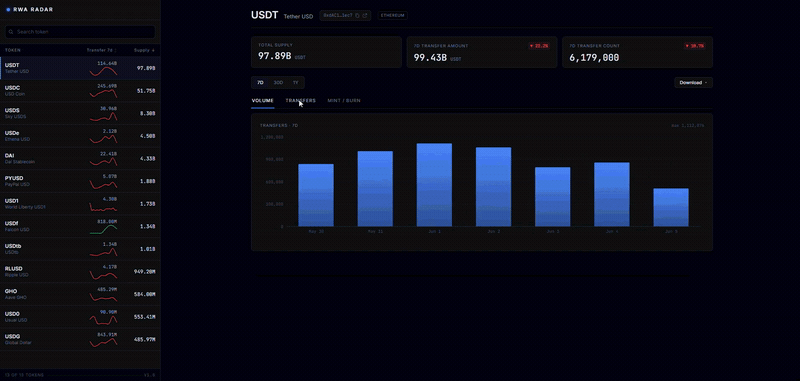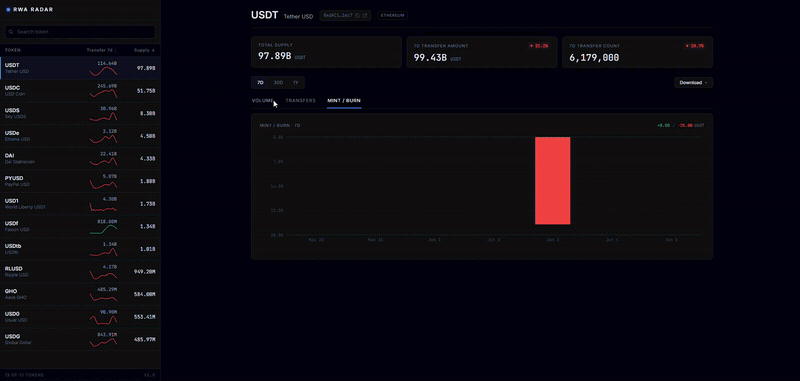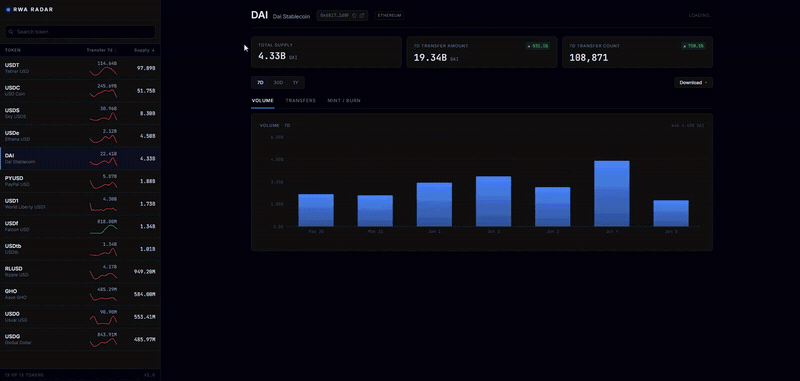
RWA Radar tracks real-world assets onchain in real time, covering stablecoins, credit, stocks, securities, and more, with sector breakdowns, volume, and history across chains in a single view, and exports to CSV, PDF, or XLSX. Ingestion is powered by HyperIndex.
Explore it here: https://rwaradar.io
When to Use HyperIndex vs HyperSync

This guide breaks down the two layers of the Envio stack, HyperSync as the data engine and HyperIndex as the framework built on top of it, with working v3 code and production examples to help teams choose the right tool for the job.
Read the full breakdown: https://docs.envio.dev/blog/hyperindex-vs-hypersync
x402stats Analytics Explorer
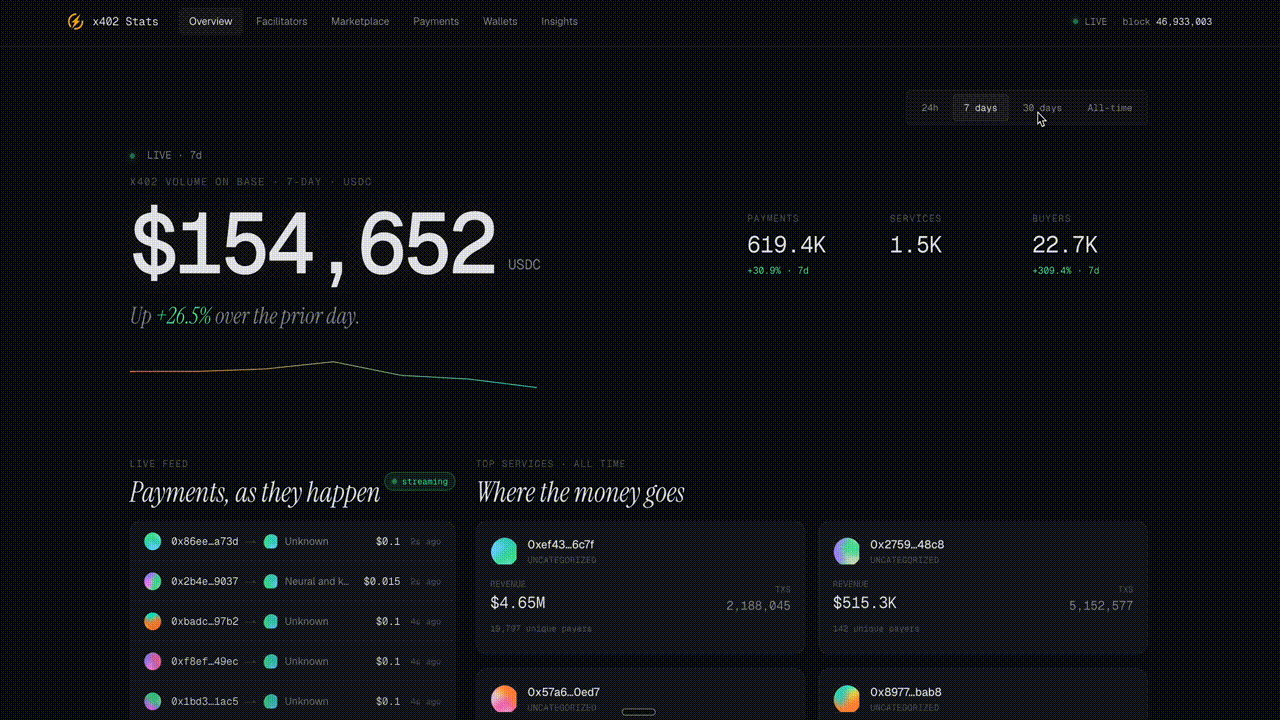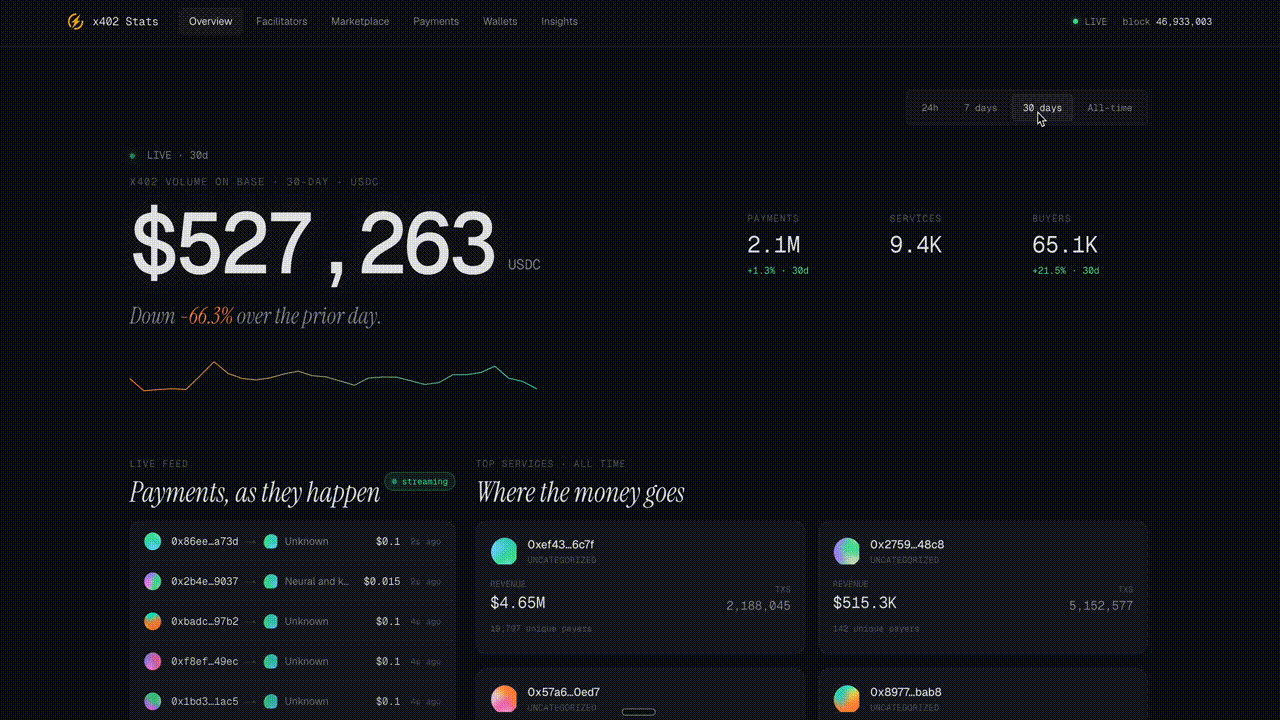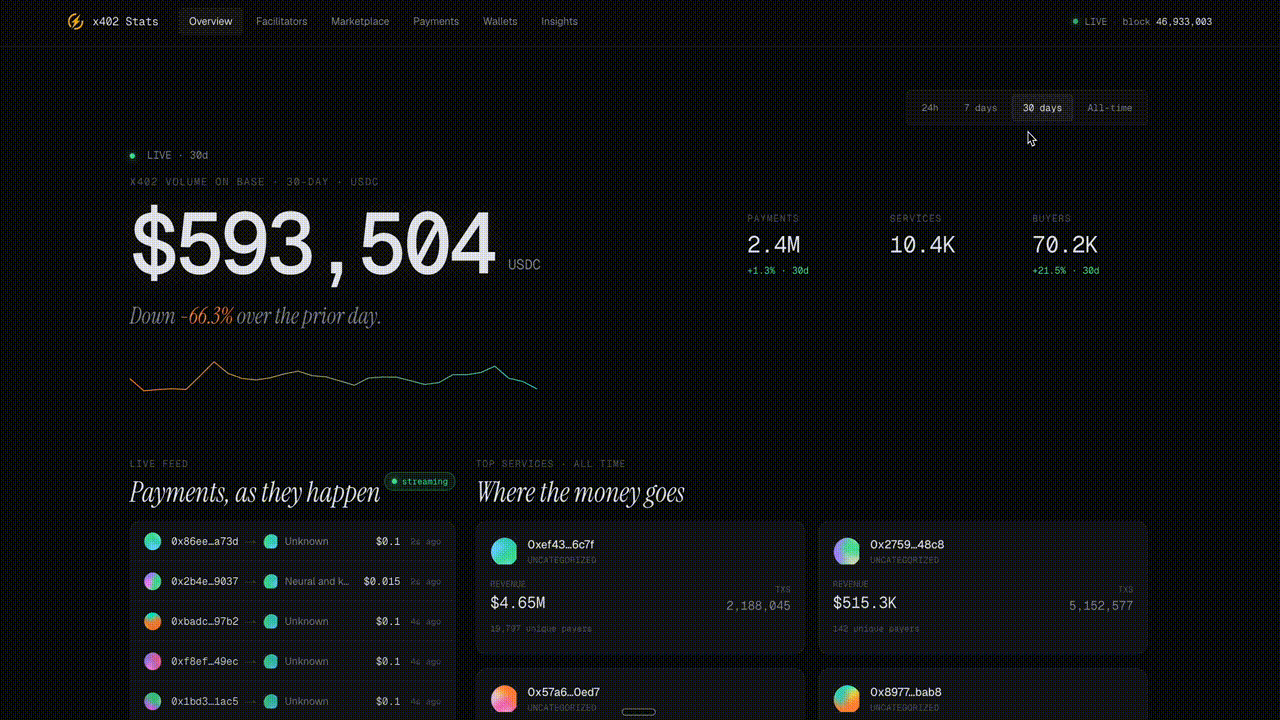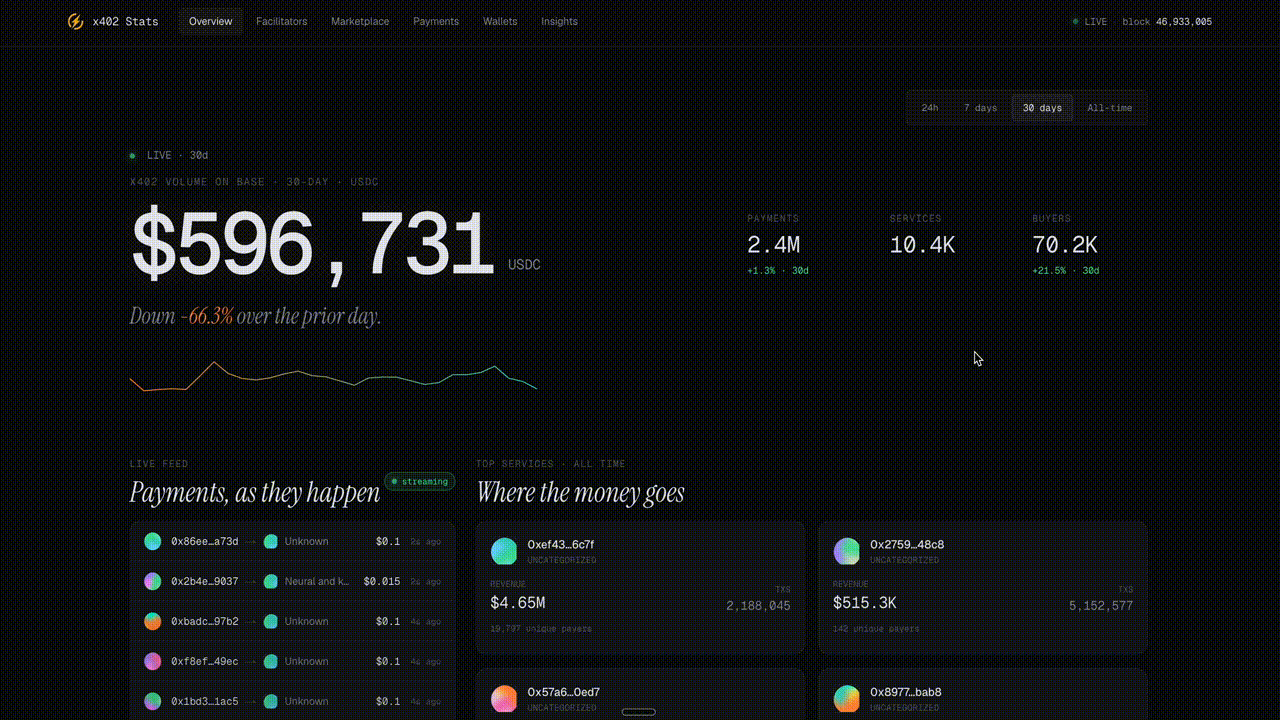
x402stats surfaces real-time stats for the x402 payment protocol on Base, including USDC volume, payment counts, active services, and buyers across 24h, 7d, 30d, and all-time, plus leaderboards for top services and facilitators.
Check it out here: https://x402stats.ai
Why Blockchain Indexers Hit Rate Limits at Scale

Why Blockchain Indexers Hit Rate Limits at Scale explains why RPC-based indexers throttle, and how HyperSync's bulk-read architecture handles high traffic, with production-scale numbers.
More here: https://docs.envio.dev/blog/hypersync-under-load-no-throttling
How to Scale Subgraphs to Millions of Requests

This one tackles the two halves of the problem, sync speed and query latency, and how HyperIndex handles both while keeping your data model intact.
Read the full guide: https://docs.envio.dev/blog/scale-subgraphs-millions-of-requests
How to Index Sei Smart Contract Data in Minutes

This step-by-step guide walks through indexing a Sei ERC20 contract, streaming USDC Transfer and Approval events into Postgres and serving them through a GraphQL API.
Read the tutorial: https://docs.envio.dev/blog/index-sei-smart-contracts-envio
ETHConf New York

We sponsored ETHConf in New York from June 8th to 10th. The team set up a booth, handed out the (back by popular demand) "low maintenance" caps and fresh stickers, and spent the week talking fast indexing, HyperSync, and pulling onchain data without the wait.
Thank you to the ETHGlobal and ETHConf teams for having us, and to everyone who stopped by to talk data.
Featured Developer: Bazhar

This month's featured developer is Bazhar, a developer and analyst focused on blockchain data, indexing, and building tools that make onchain activity easier to understand and query. Lately they have been working on approval discovery across chains, finding which wallets have approved a given contract, like a router, bridge, or Permit2-style spender, and turning that into a fast API and query layer, with most of the work centred on ERC20 approvals, spender contracts, and multichain data fast enough for production.
What Bazhar had to say about Envio:
"My experience with Envio has been really good. I came in with a fairly specific use case around discovering ERC20 approvals by spender contract across chains, and the team helped me think through the right architecture instead of just giving a generic answer. What stood out to me was how practical the support was. They explained where an indexer makes sense, where HyperSync can be used directly, and also clarified the important limitation around "live" allowances that Approval events alone don't always reflect the remaining allowance after transferFrom calls. That helped me understand the trade-offs between preindexing everything, querying HyperSync on demand, and using RPC checks only where needed. Overall, Envio feels very developer-friendly. The team was responsive, honest about the technical and cost trade-offs, and helped turn a rough idea into a much clearer implementation path."
Well done, Bazhar. Be sure to check out their GitHub to stay up to date with their latest developments.
Playlist of the Month
Build With Envio
Envio is a multichain EVM blockchain indexer for querying real-time and historical data. If you're working on a Web3 project and want a smoother development process, Envio's got your back(end). Check out our docs, join the community, and let's talk about your data needs.
Stay tuned for more monthly updates by subscribing to our newsletter, following us on X, or hopping into our Discord for more up-to-date information.
Website | X | Discord | Telegram | GitHub | YouTube | Reddit