When to use HyperIndex vs HyperSync
 Jordyn Laurier
Jordyn Laurier
- HyperSync and HyperIndex are two layers of the same stack. HyperSync is the data engine, HyperIndex is the framework built on it.
- HyperSync is a Rust data-retrieval layer that replaces JSON-RPC, up to 2000x faster, with a query, filter, and field-selection model and client libraries for TypeScript/Node.js, Python, Rust, and Go.
- HyperIndex is a full framework that turns events into a Postgres database and GraphQL API, with a config file, schema, handlers, automatic reorg handling, factory contract support, and managed hosting.
- Reach for HyperIndex when you need a persistent, queryable, reorg-safe dataset behind an API. Reach for HyperSync when you want raw data in your own pipeline, traces, or chain-wide scans.
- Because HyperIndex runs on HyperSync, you can use both. Run the framework for your backend and drop to the engine for the jobs that do not fit a schema.
At some point every onchain product needs the same thing. It needs to read data off a chain that was designed for sequential writes, not efficient reads. Envio ships two tools for that job at different layers of the stack, and the right choice depends on how much of the data pipeline you want to own.
In this blog we'll walk through what HyperSync and HyperIndex each are, the architecture that connects them, the code you actually write for each, the production systems running on them today, and a decision framework grounded in those mechanics.
How the Two Layers Relate
HyperSync is the data engine. It is written in Rust and delivers up to 2000x faster data access than JSON-RPC across 82+ EVM chains and Fuel. You describe the logs, transactions, traces, or blocks you want, and it streams them back.
HyperIndex is the framework that sits on top. It uses HyperSync as its primary data source, then adds a config file, a schema, event handlers, multichain coordination, automatic reorg handling, and a GraphQL API. HyperRPC is an abstraction layer on top of HyperSync that exposes a standard JSON-RPC interface, making it a drop-in replacement for a traditional RPC endpoint in existing code.
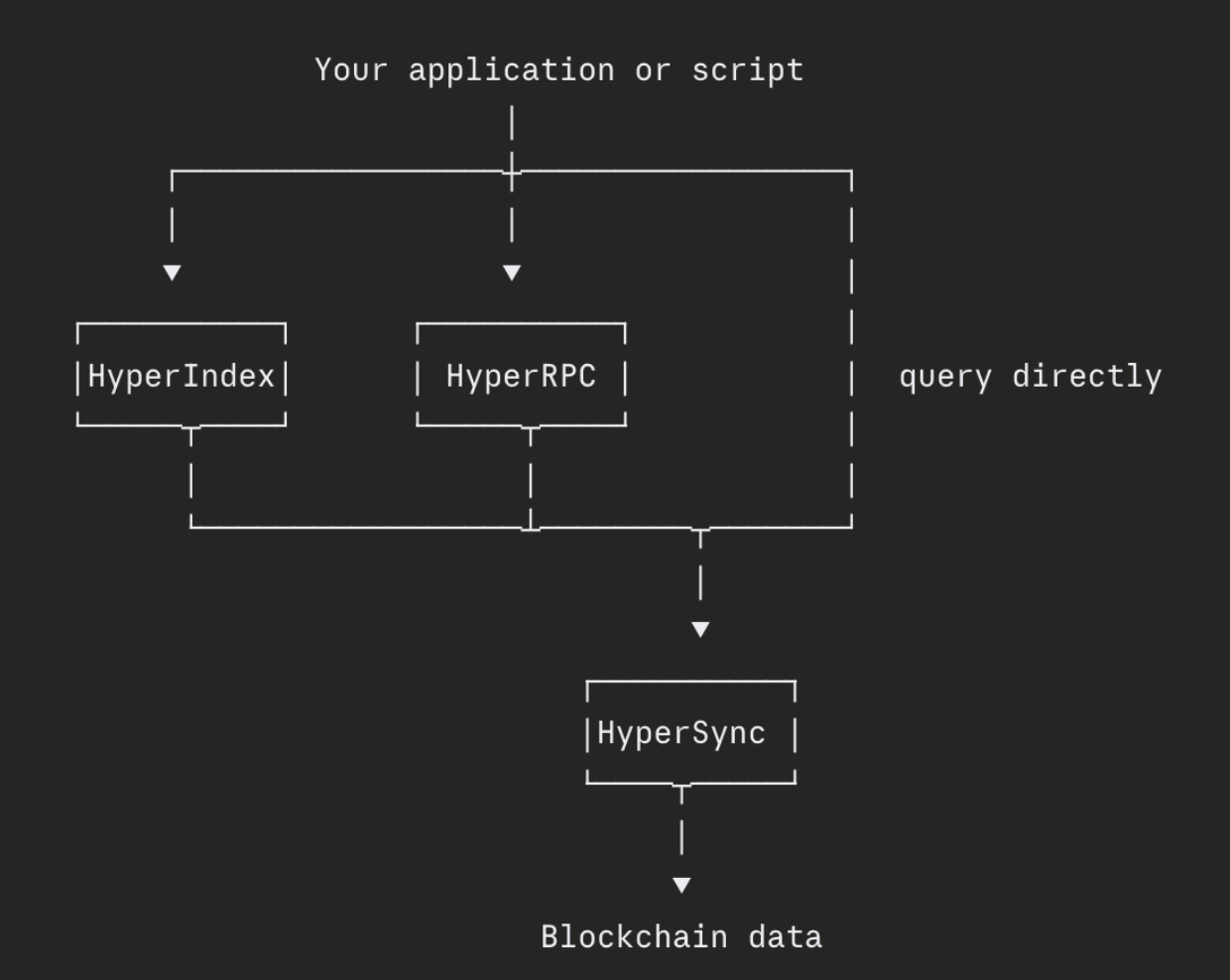
The Envio data stack. Your application can reach the chain three ways, through the HyperIndex framework, through HyperRPC's JSON-RPC interface, or by querying the HyperSync engine directly. All three sit on the same HyperSync engine, which does the actual work of retrieving data from the blockchain.
The practical consequence of this layering is that raw retrieval speed is not the axis you choose on. All three paths pull data through the same engine. What changes is how much of the pipeline, storage, and API you build yourself.
HyperSync: The Data Engine
HyperSync gives you the data and nothing else. There is no database, no schema, no API layer, and no hosting. There is a query interface, a fast stream of results, and whatever you build downstream.
You work with a small set of primitives. A query is a single object describing a block range, a filter section, and a field selection. Filters narrow results across logs, transactions, traces, and blocks. Field selection returns only the columns you ask for, which keeps responses small and credit usage low. Output modes decide how you consume results, with client.stream() for in-memory processing, client.collect_json() for small datasets, and client.collect_parquet() for analytical workloads.
A useful way to see what the engine unlocks is native ETH transfers. They do not emit event logs, so the only way to track them is by reading execution traces, which is slow and awkward over RPC. HyperSync exposes trace filtering directly. The example below streams call traces on Ethereum using the trace-enabled endpoint, taken from the native ETH transfers tutorial.
import { HypersyncClient, type TraceField } from "@envio-dev/hypersync-client";
const client = new HypersyncClient({
url: "https://eth-traces.hypersync.xyz",
apiToken: process.env.ENVIO_API_TOKEN!,
});
let query = {
fromBlock: 22000000,
traces: [{ callType: ["call"] }],
fieldSelection: {
trace: ["From", "To", "Value", "CallType", "BlockNumber"] as TraceField[],
},
};
const stream = await client.stream(query, {});
while (true) {
const res = await stream.recv();
if (res === null) break;
if (res.data?.traces) {
console.log(`Got ${res.data.traces.length} traces`);
}
if (res.nextBlock) {
query.fromBlock = res.nextBlock;
}
}
Two mechanics in that loop are worth calling out. Filtering on callType rather than trace kind lets the engine skip irrelevant trace types upfront. Feeding res.nextBlock back into the query is the standard way to page through a large range, since a single request has a processing window and returns where it stopped. Trace endpoints are available on a growing set of chains, so check the supported networks page for the current list.
Switching chains is a one-line change to the URL, and the same client works against any supported network. Client libraries ship for TypeScript/Node.js, Python, Rust, and Go, plus a curl interface for quick testing.
In production, HyperSync is the layer behind tools that would be impractical on RPC. ChainDensity.xyz scans entire chains to render transaction and event density for any address in seconds. Scope.sh is an Account Abstraction block explorer that leans on HyperSync for fast historical retrieval. LogTUI is a zero-install terminal event viewer you can try right now with pnpx logtui aave arbitrum. The open-source Polymarket reference indexer used HyperSync to sync 4 billion events in 6 days.
HyperIndex: The Framework
HyperIndex turns onchain events into a structured, queryable database. You declare what to index in a config.yaml, define your data model in a schema.graphql, and write handlers that map events onto entities. The framework owns the rest, including fetching data through HyperSync, persisting to Postgres, serving GraphQL, and rolling back on reorgs.
The config file is the first step to indexing. This one tracks Approval and Transfer on the UNI token across two chains at once, straight from the configuration docs.
# yaml-language-server: $schema=./node_modules/envio/evm.schema.json
name: erc20-indexer
description: ERC-20 Indexer
contracts:
- name: ERC20
events:
- event: "Approval(address indexed owner, address indexed spender, uint256 value)"
- event: "Transfer(address indexed from, address indexed to, uint256 value)"
chains:
- id: 1 # Ethereum Mainnet
start_block: 0
contracts:
- name: ERC20
address: "0x1f9840a85d5aF5bf1D1762F925BDADdC4201F984" # UNI
- id: 100 # Gnosis Mainnet
start_block: 0
contracts:
- name: ERC20
address: "0x4537e328Bf7e4eFA29D05CAeA260D7fE26af9D74" # UNI
Notice there is no RPC URL. For chains supported by HyperSync, it is the primary data source out of the box, and you can add an RPC entry purely as a fallback. Setting start_block to 0 is safe because HyperSync fast-forwards to the first block that holds data for your contracts.
The schema defines the entities you query.
type Transfer {
id: ID!
from: String!
to: String!
value: BigInt!
}
The handler maps each event onto those entities. This is the full v3 mental model, where you describe what an event means for your data and the framework keeps the database current.
import { indexer } from "envio";
indexer.onEvent(
{ contract: "ERC20", event: "Transfer" },
async ({ event, context }) => {
context.Transfer.set({
id: `${event.chainId}_${event.block.number}_${event.logIndex}`,
from: event.params.from,
to: event.params.to,
value: event.params.value,
});
},
);
Three framework features do real work here that you would otherwise build by hand.
Factory contracts are handled with a contractRegister handler. When a factory emits a creation event, you register the new contract address and the framework starts indexing it, including events in the same block as the creation. This is how Envio indexes data from over 1M dynamically registered contracts.
import { indexer } from "envio";
indexer.contractRegister(
{ contract: "NftFactory", event: "SimpleNftCreated" },
({ event, context }) => {
context.chain.SimpleNft.add(event.params.contractAddress);
},
);
External calls run through the Effect API, which batches and memoizes requests so a network call inside a handler does not become a per-event bottleneck. You define an effect once with optional caching and rate limiting, then call it from any handler.
import { indexer, createEffect, S } from "envio";
const getMetadata = createEffect(
{
name: "getMetadata",
input: S.string,
output: { description: S.string, value: S.bigint },
cache: true,
rateLimit: { calls: 5, per: "second" },
},
async ({ input }) => {
const response = await fetch(`https://api.example.com/metadata/${input}`);
const data = await response.json();
return { description: data.description, value: data.value };
},
);
Reorg handling is automatic. rollback_on_reorg defaults to true, so the indexer detects reorganisations and rolls affected entities back without you writing recovery logic. You can also keep the indexer a few blocks behind the head with block_lag if you want extra safety, or store entities in ClickHouse alongside Postgres for analytics workloads.
On performance, HyperIndex is the fastest indexer in independent testing. In Sentio's May 2025 benchmark of the Uniswap V2 Factory case, it finished in 8 seconds, 15x faster than the nearest competitor (Subsquid) at 2 minutes, 142x faster than The Graph at 19 minutes, and 157x faster than Ponder at 21 minutes. Historical backfills run at 30,000+ events per second. The full table is on the benchmarks page, and the open-indexer-benchmark repo lets you reproduce it.
In production, the framework shows up wherever a team needs a backend rather than a script. Sablier replaced 12 separate indexer deployments with one multichain indexer now spanning 27 chains. The Polymarket case study consolidated 8 subgraphs into a single indexer on Polygon. Revert Finance synced a PancakeSwap V3 dataset on BNB Smart Chain that had been stuck at 70% on The Graph for over two years, reaching 100% in 10 days across 1.7 billion events.
The Decision, by Mechanics
The choice follows from the architecture. HyperIndex gives you a persistent, structured store and an API in exchange for working within a schema and handler model. HyperSync gives you raw data and total control in exchange for building storage and any API yourself. The table maps concrete needs onto the layer that serves them.
| If your need is... | Use | Why, mechanically |
|---|---|---|
| A queryable backend or dashboard API | HyperIndex | You get Postgres plus a GraphQL endpoint without building either |
| One config, one API across many chains | HyperIndex | Multichain indexing from a single config.yaml and one GraphQL endpoint |
| Reorg-safe state at the head of the chain | HyperIndex | rollback_on_reorg and real-time indexing are built in |
| Indexing factory-deployed contracts | HyperIndex | contractRegister discovers and tracks new addresses automatically |
| No infrastructure to run | HyperIndex | Deploy to Envio Cloud, or self-host with Docker |
| A one-off scan or research script | HyperSync | Query and stream, with no schema or database to set up |
| ETL into a data warehouse | HyperSync | collect_parquet writes analytical output directly |
| Trace data | HyperSync | Trace filtering on trace-enabled endpoints, outside the event-log model |
| A custom monitor with your own storage | HyperSync | The thinnest layer between you and the data, in any supported language |
| Speeding up existing RPC calls, no rewrite | HyperRPC | Drop-in JSON-RPC, up to 5x faster on data-heavy reads |
A shorter version of the same logic. If you would otherwise stand up a database, a GraphQL server, and reorg handling, use HyperIndex, because it already did that work. If you would otherwise fight a framework to get at raw data, use HyperSync, because that is all it returns.
Using HyperIndex & HyperSync Together
The layering means these are not exclusive choices, and many teams run both. A common split is HyperIndex for the application backend that powers the product and HyperSync directly for a side workload, such as a nightly Parquet export or an internal analytics dashboard. The product gets a managed API, the data team gets raw access, and both ride the same engine.
The other common path is to start with HyperIndex and reach for HyperSync only when a specific need appears, like a one-off backfill or a monitoring script that does not belong in your indexer. Because HyperIndex already runs on HyperSync, dropping to the raw engine for one job is a natural step rather than a migration.
Where HyperRPC Fits
HyperRPC is the option for existing RPC-based code you do not want to rewrite. It is an abstraction over HyperSync that exposes a standard JSON-RPC interface, supporting methods like eth_getLogs, eth_getBlockByNumber, and eth_getTransactionReceipt, with early benchmarks showing up to 5x improvement over traditional nodes like geth, erigon, and reth on data-heavy reads.
Use it when you need a drop-in speed boost for tooling that expects standard JSON-RPC. For new projects where you design the data layer, the docs recommend HyperSync, because it is faster and far more flexible. Neither HyperRPC nor HyperSync can send transactions; both are read paths, and you still need a standard RPC for writes.
How to Try Each
To feel HyperSync with zero install, run the LogTUI event viewer.
pnpx logtui aave arbitrum
To scaffold a full indexer with config, schema, handlers, and a GraphQL API, initialise a HyperIndex project.
pnpx envio init
Both paths use HyperSync, which requires an API token. Indexers deployed to Envio Cloud have special access and do not need a custom token.
Frequently Asked Questions
I already run a HyperIndex indexer. When would I ever query HyperSync directly?
When you have a data job that does not belong in your indexer. HyperIndex keeps a structured, reorg-safe dataset in sync for your application, but a one-off Parquet export, a chain-wide scan for sparse data, or a standalone monitoring script with custom logic are all lighter on raw HyperSync. Since HyperIndex already uses HyperSync as its data source, you are reaching one layer down for a specific task rather than replacing anything.
Is HyperIndex slower than querying HyperSync directly?
For backfilling and serving structured data, no. HyperIndex uses HyperSync as its primary data source and adds preload optimization on top, so the framework layer manages schema, storage, reorgs, and the API rather than slowing retrieval. Raw HyperSync only feels faster on narrow tasks where you deliberately skip building a database and API, such as a streaming script.
Do I have to run my own database with HyperSync?
If you want to persist what you pull, yes. HyperSync streams data to you and stores nothing on your behalf, so you bring your own storage, whether that is Postgres, a Parquet file, or a warehouse. HyperIndex is the layer that gives you a managed Postgres database and GraphQL API without setting one up.
Which layer handles factory contracts and dynamic addresses?
HyperIndex, through the contractRegister handler. You register a contract type without an address in config.yaml, then call context.chain.<Contract>.add(address) when a factory event fires, and the framework indexes every instance, including events in the creation block. Doing the equivalent on raw HyperSync means tracking the address set and filtering queries yourself.
How do I track native ETH transfers, which do not emit logs?
Query traces on HyperSync. Native transfers only appear in execution traces, so you filter on callType: ["call"] against a trace-enabled endpoint like https://eth-traces.hypersync.xyz and stream the results. Check the supported networks page for the current list.
Can I start with HyperIndex and move a workload to HyperSync later?
Yes. Starting with HyperIndex gets a working backend up quickly, and because it runs on HyperSync, moving a specific workload to the raw engine later is straightforward. Most teams end up using each where it fits rather than committing to one for everything.
Does HyperIndex handle reorgs, or do I build that myself?
HyperIndex handles them automatically. rollback_on_reorg defaults to true, so the indexer detects a reorganisation and rolls affected entities back without recovery code. On raw HyperSync, you would design reorg handling yourself, which is one of the main reasons to use the framework for stateful backends.
Build With Envio
Envio is a real-time multichain blockchain indexer that turns onchain events into a queryable GraphQL API. Supports any EVM chain, plus Solana and Fuel. Use Envio Cloud or self-host. If you're building onchain, come talk to us about your data needs.
Website | X | Discord | Telegram | GitHub | YouTube | Reddit