Envio Developer Update May 2026
 Jordyn Laurier
Jordyn Laurier
May was our biggest month yet. After five months of alpha and release candidates, HyperIndex V3 officially shipped, production-ready, faster, and the foundation for everything we build next. Alongside it we went live on Katana, published four large-scale case studies (Polymarket, Revert Finance, Privacy Pools, and Katana's SushiSwap migration off The Graph), and shipped a stack of deep-dive guides on HyperSync, production reliability, and building onchain with AI.
We also joined Monad's Devrel livestream to talk HyperIndex, started rolling out HyperSync rate limits ahead of paid plans, and confirmed our ETHConf New York sponsorship in June.
Let's dive in!
HyperIndex V3 Is Here

After five months of alpha, HyperIndex V3 officially shipped. This is the biggest release in the framework's history, a full modernisation that bundles five months of work into a stable, production-ready release. A unified handlers API, ESM with top-level await, a purpose-built testing framework, 3x faster historical sync, Solana support, ClickHouse as a second storage backend, and a much smaller package. With V3 we are back to following SemVer and set up for the next year of features.
To upgrade an existing project, follow the Migrate to V3 guide. For the complete rundown, see What's New in V3.
Unified Handlers API
All handler registrations now flow through a single indexer value. Contract-specific exports are replaced by indexer.onEvent, indexer.contractRegister, and indexer.onBlock.
import { indexer } from "envio";
indexer.onEvent(
{
contract: "ERC20",
event: "Transfer",
wildcard: true,
where: ({ chain }) => ({
params: [
{ from: chain.Safe.addresses },
{ to: chain.Safe.addresses },
],
}),
},
async ({ event, context }) => {
// Handler logic
},
);
3x Faster Historical Backfill
We added chunking logic to request events across multiple ranges at once, removed overfetching for contracts with a much later start block, and sped up dynamic contract registration.
25k events per second is now standard.
A Purpose-Built Testing Framework
HyperIndex now ships its own testing framework powered by createTestIndexer(). You write tests against the same indexer that runs in production, with no database, no Docker, and no manual mock wiring. It integrates with Vitest, includes snapshot testing out of the box, and gives you three ways to feed events (auto-exit, explicit block range, or simulate).
import { describe, it } from "vitest";
import { createTestIndexer } from "envio";
describe("ERC20 indexer", () => {
it("processes the first block with events", async (t) => {
const indexer = createTestIndexer();
const result = await indexer.process({ chains: { 1: {} } });
// Auto-filled by Vitest on first run -- just review and commit
t.expect(result).toMatchInlineSnapshot(`
{
"changes": [
{
"Transfer": {
"sets": [
{
"blockNumber": 10861674,
"from": "0x0000000000000000000000000000000000000000",
"id": "1-10861674-23",
"to": "0x41653c7d61609D856f29355E404F310Ec4142Cfb",
"transactionHash": "0x4b37d2f343608457ca...",
"value": 1000000000000000000000000000n,
},
],
},
"block": 10861674,
"chainId": 1,
"eventsProcessed": 1,
},
],
}
`);
});
});
ESM and Top-Level Await
We migrated HyperIndex from CommonJS to ESM. That unlocks the latest versions of libraries that dropped CommonJS long ago, and lets you use await directly at the top of your handler files.
Solana Support (Experimental)
HyperIndex now supports Solana with RPC as a source. Spin up a Solana project with pnpx envio init svm. Solana exposes its block-stream handler as indexer.onSlot rather than onBlock, matching Solana's slot-based model.
ClickHouse as an Additional Storage Backend (Experimental)
HyperIndex can now run with multiple storage backends side by side. Postgres remains the primary database, and entities can additionally be written to a ClickHouse database that is restart and reorg resistant. Enable it in config.yaml and route each entity via the @storage directive in schema.graphql.
storage:
postgres: true
clickhouse: true
Envio Cloud supports ClickHouse on the Dedicated Plan.
A Much Smaller Package and Bun Support
You can run HyperIndex on Bun with bun --bun envio dev, and we removed the runtime ReScript compiler from the published package by eliminating dynamically generated ReScript code.
The envio npm package shrank from 141MB to 53MB.
Agentic Mode in envio init
envio init now ships an agentic mode. When an AI coding assistant runs the command, it produces an AI-readable guiding prompt instead of a TTY error, so the agent knows exactly how to scaffold an indexer end to end.
Welcome to Envio Indexer! Let's set up an indexer that will become a reliable blockchain backend you trust, love, and own.
Leave the rest to your favorite agent:
1. Prompt the user for the project intent if it is missing from context (what should the indexer track and surface?).
2. Determine the chain, contract, and addresses needed to produce that result. Use web search or block-explorer tool calls when the user hasn't supplied them.
3. To continue, call:
pnpx envio init contract-import explorer \
-n ${indexer-name} \
-c ${address} \
-b ${chainId} \
--single-contract \
--all-events \
-d ${directory}
Then `cd ${directory}` and run `pnpm test`. Don't hand the project off yet -- keep iterating on the indexer with a TDD loop (extend tests, run them, fix handlers) until the user's goal is met.
See the full release notes
Star us on GitHub ⭐
Envio is Live on Katana

We launched production-grade indexing on Katana, the DeFi-first chain built where liquidity concentrates and real yield flows back to users. Developers can now access real-time and historical onchain data on Katana, up to 2000x faster than RPC.
Easy, fast, and fully customisable.
Original post on X: https://x.com/katana/status/2056389958303441051
Indexing 4 Billion Polymarket Events

We replaced Polymarket's eight production subgraphs, four years of fragmentation across separate AssemblyScript codebases on The Graph, with a single HyperIndex indexer written in TypeScript. Over 4 billion events synced in 6 days on Polygon.
The unlock is handler merging. A shared contract event like ConditionalTokens.PositionSplit previously fired across three or four separate subgraphs. In the unified indexer, one handler fires once and updates open interest, activity, and PnL together. That is 25+ entity types behind a single GraphQL endpoint, and one deployment to maintain instead of eight. The full indexer is open source as a reference for any team migrating from The Graph.
Read the case study: https://docs.envio.dev/blog/polymarket-hyperindex-case-study
Revert Finance Fixed 2 Years of Unsynced PancakeSwap V3 Data

Revert Finance builds analytics and management tools for AMM liquidity providers. Their PancakeSwap V3 subgraph on BNB Smart Chain had been stuck at 70% sync for over two years, unable to reach chain head, because the chain's throughput outpaced what RPC-based indexing could sustain.
We built a HyperIndex indexer covering the full PancakeSwap V3 contract surface on BNB Smart Chain. 1,711,569,200 events synced to 100% in 10 days.
Read the case study: https://docs.envio.dev/blog/revert-finance-pancakeswap-bnb-hyperindex
Privacy in Public, Indexing Privacy Pools

Privacy Pools is a privacy primitive co-authored by Vitalik Buterin that pairs a zero-knowledge proof of pool membership with an off-chain compliance layer. We indexed every deposit, withdrawal, ragequit, ASP root update, and relayer fee across all 21 live pools on four chains (Ethereum, Optimism, BSC, and Arbitrum) with a single HyperIndex indexer using dual Postgres and ClickHouse storage.
Full multichain sync to head in roughly 30 seconds, and 91% of withdrawals use the privacy-preserving relayed path. The full stack, including the indexer, the analytics queries, and the BI report generator, is open source under MIT license. It is a great example of multichain coverage and an analytics-grade columnar store as first-class features.
Read the case study: https://docs.envio.dev/blog/privacy-in-public-case-study
Katana Migrates SushiSwap Off The Graph

Katana migrated two production subgraphs, SushiSwap V3 and the Sushi staker, from The Graph to Envio HyperIndex without disrupting the app surfacing the data. Katana's existing subgraph-style queries kept working through Envio's subgraph-compatible endpoint, and for the full GraphQL feature set its app needed, Katana moved onto Envio's native endpoint, with our team supporting the move directly.
SushiSwap V3 synced 11,473,382 events in about two hours, and the Sushi staker synced 68,201 events in under 20 seconds.
Read the case study: https://docs.envio.dev/blog/case-study-katana-sushiswap
What is HyperSync?

Reading onchain data over standard JSON-RPC breaks down the moment you need fast, filtered, or multichain historical data. HyperSync is our high-performance data retrieval layer built to fix exactly that. It is written in Rust, uses optimised binary encoding and parallel fetching, and exposes a single query interface across every supported chain.
Scanning Arbitrum for sparse log data takes 2 seconds with HyperSync, up to 2000x faster than RPC. HyperSync is the engine behind HyperIndex. Client libraries are available for TypeScript, Python, Rust, and Go. This blog covers what it is, how it works, and how to use it in your own application.
Learn more here: https://docs.envio.dev/blog/what-is-hypersync
Production Indexer Reliability with HyperIndex

Speed wins benchmarks, but reliability is what keeps an indexer running for years. This post walks through the four reliability guarantees HyperIndex provides at the framework level, so any indexer built on it inherits them without writing operational code. Those guarantees are built-in reorg handling with automatic rollback, restart-resistant operation, HyperSync data validation, and multi data-source recovery.
Reorgs are handled automatically by tracking entity state history for every unfinalized block and rolling back without any custom handler logic. Multi data-source recovery fails over to a fallback within seconds and recovers to the primary 60 seconds later. Observability comes through a semver-stable Prometheus endpoint.
More here: https://docs.envio.dev/blog/production-indexer-reliability-hyperindex
Why AI Agents Acting Onchain Need an Indexer

SQL warehouses let agents ask. Indexers let them act. An agent reading raw RPC hits four walls quickly, namely reorgs, no schema, low throughput, and per-chain quirks at multichain scale. A SQL warehouse fronted by an LLM solves the read side, but an agent acting onchain needs to build, deploy, and own new data pipelines mid-session, not just query existing ones.
This post makes the case for a programmable indexer over a query layer, backed by the docs MCP server, the auto-discovered .claude/skills/ directory, and the GitHub-native deploy flow.
One prompt, roughly 20 seconds, 400,000 events indexed on Monad.
Read the full breakdown: https://docs.envio.dev/blog/ai-agents-acting-onchain-indexer
AI-Assisted Subgraph Migration to HyperIndex with Claude

The hardest part of moving off The Graph has always been the AssemblyScript rewrite. With the docs MCP server and the dedicated migrate-from-subgraph skill shipped in every HyperIndex project, Claude can handle the AssemblyScript-to-TypeScript translation end to end while a developer reviews the diff, runs the tests, and ships the indexer.
This guide walks the full workflow on a real surface area, anchored to the open-source Polymarket reference. A migration that used to take weeks becomes a one or two day exercise.
Read the full tutorial: https://docs.envio.dev/blog/ai-subgraph-migration-hyperindex-claude
Build an AI-Powered Onchain App with HyperIndex and Claude

A practical, end-to-end walkthrough of building a multichain HyperIndex indexer with Claude as a pair programmer. It covers wiring up the docs MCP server, scaffolding the project, making it multichain, writing the schema and handlers, running locally, and deploying to Envio Cloud through the GitHub-native flow.
Every command is reproducible against the current release, and the patterns come straight from the public Polymarket reference indexer. With Claude driving, you can go from a blank project to a deployed, queryable indexer in minutes.
More here: https://docs.envio.dev/blog/ai-onchain-app-hyperindex-claude
Migrating from Ponder to Envio

Both Ponder and HyperIndex are TypeScript-first and expose a GraphQL API, so migration is mostly mechanical translation. Three things change. ponder.config.ts becomes config.yaml, ponder.schema.ts becomes schema.graphql, and event handlers adapt to the HyperIndex entity API. This guide walks all three steps end to end, with every code block taken from the official migration reference.
Up to 157x faster historical sync via HyperSync, with multichain support by default.
For teams looking for a clear path forward, our team supports the migration end to end, from planning the rewrite to getting the indexer live on Envio Cloud.
Read the full tutorial: https://docs.envio.dev/blog/migrate-from-ponder-to-envio
HyperSync Rate Limits
Throughout May we have been rolling out HyperSync rate limits more aggressively. Limits ratchet down gradually so you get the smoothest possible transition to paid plans without disruption to your services. Keep an eye out for 429 rate limit exceeded errors.
If you are already on a paid HyperSync plan, your normal plan limits apply and no action is needed. If you are not on a paid plan yet, get sorted as soon as possible by opening a Discord ticket to arrange one with the team, or by picking a plan directly.
This affects all HyperSync users and anyone self-hosting HyperIndex with a HyperSync token. Envio Cloud deployments are not affected.
Polymarket's Top Traders Run on Indexed Data

Co-founder Jonjon Clark published a data-driven series profiling the top 100 Polymarket traders by realised PnL, and the deeper he digs, the clearer it becomes that these operations live or die on fast, real-time access to onchain data, exactly the workload HyperIndex and HyperSync are built for. Here are a few that stand out.
The 95% Win Rate Trader
$23.6M in realised PnL and a 95.4% win rate. It runs a live NBA model that prices games faster than the order book, pre-positions on the cheap side before tip-off, and rides the eventual winner to oracle redemption.
The 15-Minute Bitcoin Loop Trader
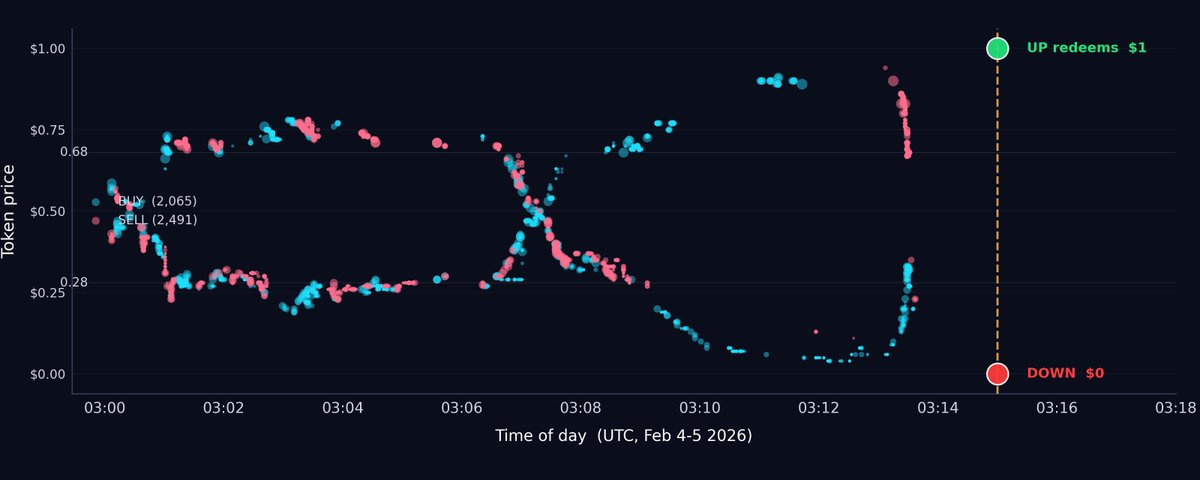
7.6 million fills across 32,021 markets in 111 days, about one fill per second, netting $2.38M. It posts resting bids on both sides of Polymarket's 15-minute BTC binaries and captures the spread off retail flow, completely indifferent to which way Bitcoin moves.
The UMA Gap Trader
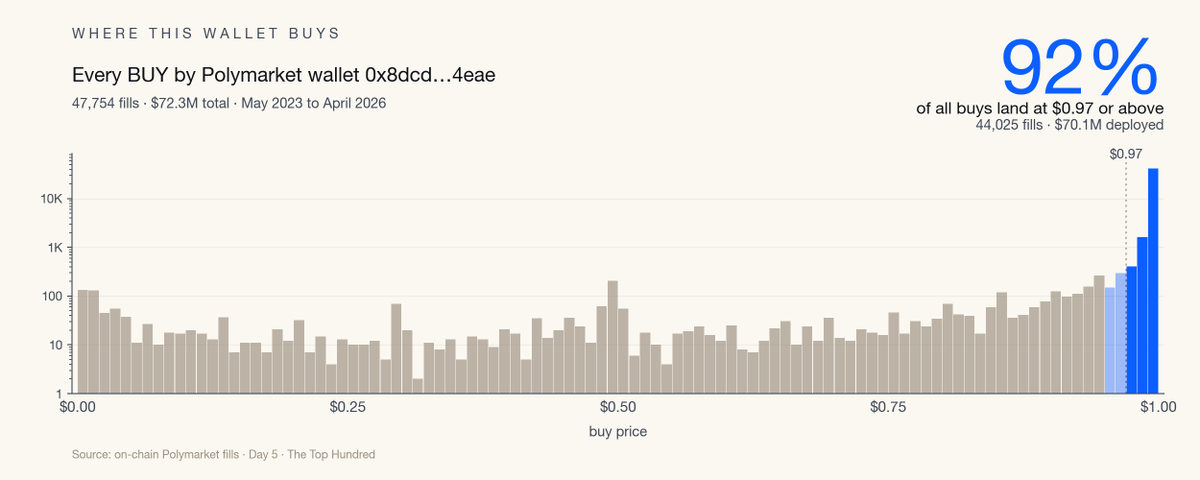
Number 26 on the leaderboard with $8M in lifetime realised PnL. Its cleanest mechanism is the settlement sweep, buying near-par winning tokens in the gap between when a result is known and when the UMA oracle finalises payout, for a 98.2% win rate across more than 4,000 positions.
Envio x Monad's Devrel Livestream
Co-founder Denham joined Monad's Devrel Livestream to chat HyperIndex on Monad, Monskills, and how to vibecode your way to a production indexer.
Missed it live? Catch the full recording on X.
Current & Upcoming Events & Hackathons
- ETHConf - New York: June 8th -> 10th (sponsoring)
Playlist of the Month
Build With Envio
Envio is a multichain EVM blockchain indexer for querying real-time and historical data. If you're working on a Web3 project and want a smoother development process, Envio's got your back(end). Check out our docs, join the community, and let's talk about your data needs.
Stay tuned for more monthly updates by subscribing to our newsletter, following us on X, or hopping into our Discord for more up-to-date information.
Website | X | Discord | Telegram | GitHub | YouTube | Reddit