Indexing IPFS Data with Envio
Example Repository: The complete code for this guide can be found here
Introduction
This guide demonstrates how to fetch and index data stored on IPFS within your Envio indexer. We'll use the Bored Ape Yacht Club NFT collection as a practical example, showing you how to retrieve and store token metadata from IPFS.
IPFS (InterPlanetary File System) is commonly used in blockchain applications to store larger data like images and metadata that would be prohibitively expensive to store on-chain. By integrating IPFS fetching capabilities into your indexers, you can provide a more complete data model that combines on-chain events with off-chain metadata.
Implementation Overview
Our implementation will follow these steps:
- Create a basic indexer for Bored Ape Yacht Club NFT transfers
- Extend the indexer to fetch and store metadata from IPFS
- Handle IPFS connection issues with fallback gateways
Step 1: Setting Up the Basic NFT Indexer
First, let's create a basic indexer that tracks NFT ownership:
Initialize the Indexer
pnpx envio init
When prompted, enter the Bored Ape Yacht Club contract address: 0xBC4CA0EdA7647A8aB7C2061c2E118A18a936f13D
Configure the Indexer
Modify the configuration to focus on the Transfer events:
# config.yaml
name: bored-ape-yacht-club-nft-indexer
chains:
- id: 1
start_block: 0
end_block: 12299114 # Optional: limit blocks for development
contracts:
- name: BoredApeYachtClub
address:
- "0xBC4CA0EdA7647A8aB7C2061c2E118A18a936f13D"
events:
- event: Transfer(address indexed from, address indexed to, uint256 indexed tokenId)
Define the Schema
Create a schema to store NFT ownership data:
# schema.graphql
type Nft {
id: ID! # tokenId
owner: String!
}
Implement the Event Handler
Track ownership changes by handling Transfer events:
// src/EventHandler.ts
import { indexer } from "envio";
const ZERO_ADDRESS = "0x0000000000000000000000000000000000000000";
indexer.onEvent(
{ contract: "BoredApeYachtClub", event: "Transfer" },
async ({ event, context }) => {
if (event.params.from === ZERO_ADDRESS) {
// mint
context.Nft.set({
id: event.params.tokenId.toString(),
owner: event.params.to,
});
} else {
// transfer
const nft = await context.Nft.getOrThrow(event.params.tokenId.toString());
context.Nft.set({
...nft,
owner: event.params.to,
});
}
},
);
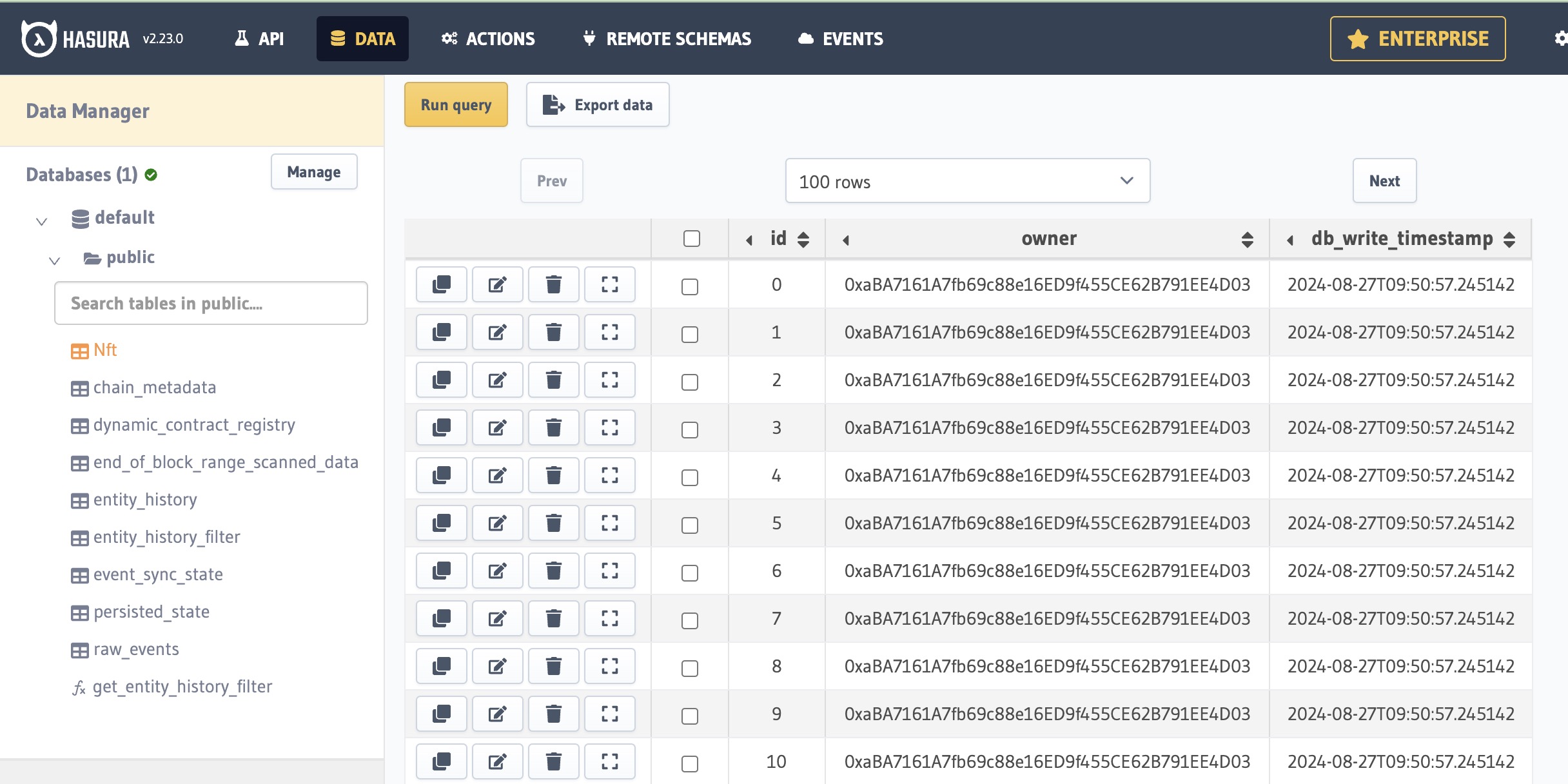
Run your indexer with pnpm dev and visit http://localhost:8080 to see the ownership data:
Step 2: Fetching IPFS Metadata
Now, let's enhance our indexer to fetch metadata from IPFS:
Update the Schema
Extend the schema to include metadata fields:
# schema.graphql
type Nft {
id: ID! # tokenId
owner: String!
image: String!
attributes: String! # JSON string of attributes
}
Create IPFS Effect
Important! Preload optimization makes your handlers run twice. So instead of direct RPC calls, we're doing it through the Effect API.
Learn how Preload Optimization works in a dedicated guide. It might be a new mental model for you, but this is what can make indexing thousands of times faster.
Let's create the getIpfsMetadata effect in the src/utils/ipfs.ts file:
import { createEffect, S, type EffectContext } from "envio";
// Define the schema for the IPFS metadata
// It uses Sury library to define the schema
const nftMetadataSchema = S.schema({
image: S.string,
attributes: S.string,
});
// Infer the type from the schema
type NftMetadata = S.Infer<typeof nftMetadataSchema>;
// Unique identifier for the BoredApeYachtClub IPFS tokenURI
const BASE_URI_UID = "QmeSjSinHpPnmXmspMjwiXyN6zS4E9zccariGR3jxcaWtq";
const endpoints = [
// Try multiple endpoints to ensure data availability
// Optional paid gateway (set in .env)
...(process.env.PINATA_IPFS_GATEWAY ? [process.env.PINATA_IPFS_GATEWAY] : []),
"https://cloudflare-ipfs.com/ipfs",
"https://ipfs.io/ipfs",
];
async function fetchFromEndpoint(
context: EffectContext,
endpoint: string,
tokenId: string
): Promise<NftMetadata | null> {
try {
const response = await fetch(`${endpoint}/${BASE_URI_UID}/${tokenId}`);
if (response.ok) {
const metadata: any = await response.json();
return {
image: metadata.image,
attributes: JSON.stringify(metadata.attributes),
};
} else {
context.log.warn(`IPFS didn't return 200`, { tokenId, endpoint });
return null;
}
} catch (e) {
context.log.warn(`IPFS fetch failed`, { tokenId, endpoint, err: e });
return null;
}
}
export const getIpfsMetadata = createEffect(
{
name: "getIpfsMetadata",
input: S.string,
output: nftMetadataSchema,
rateLimit: {
calls: 5,
per: "second",
},
},
async ({ input: tokenId, context }) => {
for (const endpoint of endpoints) {
const metadata = await fetchFromEndpoint(context, endpoint, tokenId);
if (metadata) {
return metadata;
}
}
// ⚠️ Dangerous: Sometimes it's better to crash, to prevent corrupted data
// But we're going to use a fallback value, to keep the indexer process running.
// Both approaches have their pros and cons.
context.log.warn(
"Unable to fetch IPFS. Continuing with fallback metadata.",
{
tokenId,
}
);
return { attributes: `["unknown"]`, image: "unknown" };
}
);
Update the Event Handler
Let's modify the event handler to fetch and store metadata using the getIpfsMetadata effect:
// src/handlers
import { indexer } from "envio";
import { getIpfsMetadata } from "./utils/ipfs";
const ZERO_ADDRESS = "0x0000000000000000000000000000000000000000";
indexer.onEvent(
{ contract: "BoredApeYachtClub", event: "Transfer" },
async ({ event, context }) => {
if (event.params.from === ZERO_ADDRESS) {
// mint
const metadata = await context.effect(
getIpfsMetadata,
event.params.tokenId.toString()
);
context.Nft.set({
id: event.params.tokenId.toString(),
owner: event.params.to,
image: metadata.image,
attributes: metadata.attributes,
});
} else {
// transfer
const nft = await context.Nft.getOrThrow(event.params.tokenId.toString());
context.Nft.set({
...nft,
owner: event.params.to,
});
}
},
);
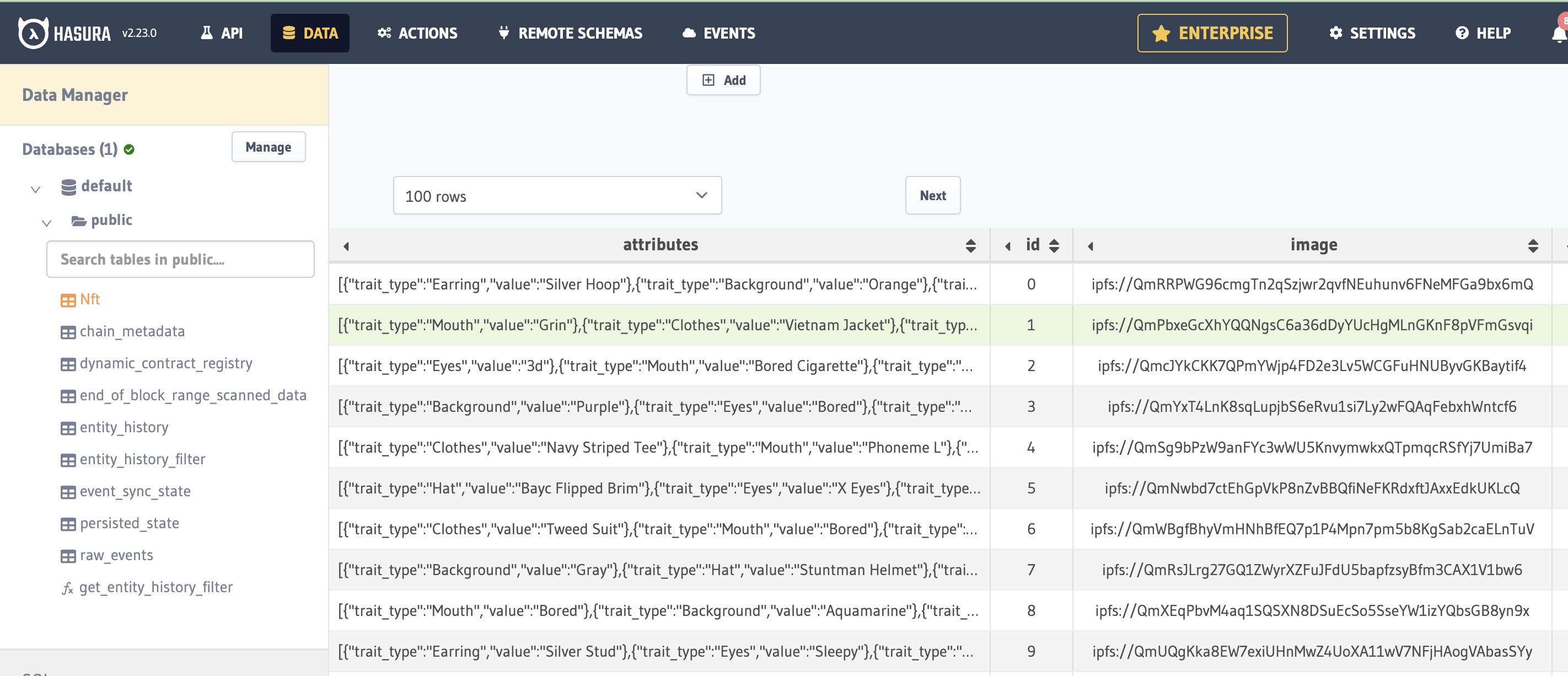
When you run the indexer now, it will populate both ownership data and token metadata:
Best Practices for IPFS Integration
When working with IPFS in your indexers, consider these best practices:
1. Use Multiple Gateways
IPFS gateways can be unreliable, so always implement multiple fallback options:
const endpoints = [
...(process.env.PAID_IPFS_GATEWAY ? [process.env.PAID_IPFS_GATEWAY] : []),
"https://cloudflare-ipfs.com/ipfs",
"https://ipfs.io/ipfs",
"https://gateway.pinata.cloud/ipfs",
];
2. Handle Failures Gracefully
Always include error handling and provide fallback values:
try {
// IPFS fetch logic
} catch (error) {
context.log.error(`Failed to fetch from IPFS`, error as Error);
return { attributes: [], image: "default-image-url" };
}
3. Implement Local Caching (For Local Development)
Follow the Effect API Persistence guide to implement caching for local development. This should allow you to avoid repeatedly fetching the same data.
export const getIpfsMetadata = createEffect(
{
name: "getIpfsMetadata",
input: S.string,
output: nftMetadataSchema,
rateLimit: {
calls: 5,
per: "second",
},
cache: true, // Enable caching
},
async ({ input: tokenId, context }) => {...}
);
Important: While the example repository includes SQLite-based caching, this approach is outdated and leads to many indexing issues.
Note: We're working on a better integration with Envio Cloud. Currently, due to the cache size, it's not recommended to commit the
.envio/cachedirectory to the GitHub repository.
4. Learn about Preload Optimization
Learn how Preload Optimization works and the Double-Run Footgun in a dedicated guide. It might be a new mental model for you, but this is what can make indexing thousands of times faster.
Understanding IPFS
What is IPFS?
IPFS (InterPlanetary File System) is a distributed system for storing and accessing files, websites, applications, and data. It works by:
- Splitting files into chunks
- Creating content-addressed identifiers (CIDs) based on the content itself
- Distributing these chunks across a network of nodes
- Retrieving data based on its CID rather than its location
Common Use Cases with Smart Contracts
IPFS is frequently used alongside smart contracts for:
- NFTs: Storing images, videos, and metadata while the contract manages ownership
- Decentralized Identity Systems: Storing credential documents and personal information
- DAOs: Maintaining governance documents, proposals, and organizational assets
- dApps: Hosting front-end interfaces and application assets
IPFS Challenges
IPFS integration comes with several challenges:
- Slow Retrieval Times: IPFS data can be slow to retrieve, especially for less widely replicated content
- Gateway Reliability: Public gateways can be inconsistent in their availability
- Data Persistence: Content may become unavailable if nodes stop hosting it
To mitigate these issues:
- Use pinning services like Pinata or Infura to ensure data persistence
- Implement multiple gateway fallbacks
- Consider paid gateways for production applications